Written by Alex Choi, Mar. 30, 2014.
목 차
-
GPU 개괄
1.1. 병렬 컴퓨터로서의 GPU
1.2. 현대 GPU의 구조
1.3. 고수준의 병렬 계산을 하는 이유?
1.4. 병렬 프로그래밍 언어와 모델
-
GPU 역사
2.1. 그래픽스 파이프라인의 진화
2.2. GPU 계산
2.3. 미래 발전 동향
-
최신 기술 동향
3.1. 다양한 분야에서의 병렬 계산
3.2. 하이브리드 GPU 기술
3.3. 통합 셰이더 기술
3.4. NVIDIA의 Fermi 아키텍쳐
3.5. NVIDIA의 Kepler 아키텍쳐
3.6. NVIDIA의 Tesla 프로세서
-
컴퓨터 그래픽스 산업 분야에서의 GPU 활용
4.1. PhysX
4.2. OptiX
4.3. SceniX
4.4. CompleX
-
맺음말
1. GPU 개괄
Intel Pentium 계열과 AMD Opteron 계열과 같은 단일 중앙처리장치(Central Processing Unit, 이하 CPU)에 기반을 둔 마이크로 프로세서들은 지난 20년간 컴퓨터 어플리케이션의 빠른 성능 개선과 비용 감소를 이끌어 왔습니다. 이러한 마이크로프로세서들은 데스크탑에서는 수 기가 플롭스(Giga floating-point operations per second, 이하 GFLOPS) 및 클러스터 서버에서는 수백 GFLOPS의 성능을 발휘합니다. 이처럼 끊임없는 성능 개선 덕분에 응용 소프트웨어들은 보다 나은 기능 및 사용자인터페이스를 가질 수 있게 되었으며 보다 유용한 결과를 창출합니다. 결국 사용자들은 이러한 발전에 익숙해 지고 시장에 보다 고성능의 어플리케이션을 요구할 것이며 이는 컴퓨터 산업의 긍정적 싸이클을 구성합니다.
대부분의 소프트웨어 개발자들은 각자가 개발한 어플리케이션의 속도 향상을 위해 하드웨어의 발전에 의존합니다. 즉, 동일한 소프트웨어 새로운 프로세서가 등장할 때마다 더욱 빠르게 구동될 수 있습니다. 그러나 하드웨어의 성능 개선 속도는 단일 CPU 내의 클럭 주기로 수행되는 클럭 주파수 향상을 제약해 온 에너지 소비와 열 방출 문제 등으로 인해 2003년 이후로 줄곧 더디게 발전해 왔습니다. 어쩔 수 없이 모든 마이크로프로세서 업자들은 프로세싱 파워 성능 향상을 위해 각 칩에 사용되는 일명 "프로세서 코어"라는 다중 프로세싱 유닛이 사용되는 모델로의 전환을 모색하기 시작했습니다. 이러한 전환은 소프트웨어 커뮤니티에 엄청난 파장을 불러 일으켰습니다.
전통적으로, 대부분의 소프트웨어 어플리케이션들은 폰 노이만(von Neumann[1945])의 보고서에 기록된 바와 같이 순차적 프로그램(sequential program)으로 작성되었습니다. 인간의 순차적 코드 스텝핑은 이러한 프로그램의 실행을 쉽게 이해할 수 있습니다. 역사적으로 컴퓨터 사용자들은 마이크로프로세서의 새로운 시대가 열릴 때마다 이러한 프로그램들이 더욱 빠르게 구동될 것으로 기대해 왔습니다. 이러한 기대는 이 시대에 더 이상 유효하지 않습니다. 순차적 프로그램은 프로세서 코어 중 하나에서만 구동될 것이며, 오늘날에는 눈에 띄게 속도의 향상을 느낄 수 없을 정도가 되었습니다. 성능 향상 없이는 어플리케이션 개발자들은 더이상 새 마이크로프로세서들이 소개될 때마다 각자가 개발한 소프트웨어로 새로운 기능을 부여하기가 불가능 해졌습니다. 따라서 전체 컴퓨터 산업의 성장 기회를 점점 빼앗기게 될 것입니다.
대신 새로운 마이크프로세서의 세대가 시작될 때마다 성능 향상을 지속할 수 있는 어플리케이션 소프트웨어는 병렬 프로그램이 될 것입니다. 병렬 프로그램은 다중의스레드를 동시에 실행하여 어플리케이션이 놀라울 정도로 빠른 속도로 구동되도록 합니다. 병렬 프로그램의 급성장은 "동시성 혁명(Concurrency revolution[Sutter 2005])"에 잘 표현되어 있습니다. 병렬 프로그래밍은 더 이상 새로운 개념이 아닙니다. 고성능 프로그램 커뮤니티는 수년간 병렬 프로그램을 개발해 왔습니다. 겨우 몇몇 엘리트 어플리케이션만이 이러한 고가의 컴퓨터 사용을 독차지하였으며 소수의 어플리케이션 개발자들만이 병렬 프로그램 사용을 연습할 수 있었습니다. 이제 모든 마이크로프로세서들이 병렬 컴퓨터이기 때문에 병렬 프로그램으로 처리하는 어플리케이션의 수는 급증하고 있습니다. 이제 소프트웨어 개발자들의 병렬 프로그램을 배우는데 대한 요구가 급속도로 증가하고 있습니다.
1.1. 병렬 컴퓨터로서의 GPU
2003년 이후로, 반도체 산업은 마이크로프로세서 설계에 있어 두 가지 주요 흐름을 형성하였습니다 [Hwu 2008]. "다중 코어(Multi-core)"에 대한 흐름에 있어서는 멀티코어로 전환되는 동안 순차적 프로그램의 실행 속도를 유지하려고 합니다. 멀티코어는 각 반도체 프로세스 세대마다 약2대의 코어 수를 갖는 two-core 프로세서로 시작되었습니다. 현재 대표적으로 꼽을 수 있는 것은 최근의 Intel Core i7 마이크로프로세서이며, 이는 네 개의 프로세서 코어를 가지고 있습니다. 마이크로프로세서는 두 개의 하드웨어 스레드를 갖는 하이퍼스레딩을 지원하며 순차적 프로그램의 실행 속도를 최대화할 수 있도록 설계되었습니다.
반면 "다수 코어(Many-core)"에 대한 흐름은 병렬 어플리케이션의 실행 처리량에 더욱 무게를 둡니다. 다수 코어는 많은 수의 보다 작은 코어로 시작되었습니다. 현재 대표적인 것으로 240개의 코어를 갖는 nVdiaGeForce GTX 280 그래픽스 처리 장치(Graphics Processing Unit, 이하 GPU)를 꼽을 수 있으며 각 코어는 엄청난 멀티스레딩으로 동작하며 다른 7개의 코어와 제어와 명령을 공유합니다. 다수 코어, 특히 GPU는 2003년 이후 줄곧 부동 소수 성능 경쟁을 이끌어 왔습니다. 이러한 현장은 그림 1.1에 나타나 있습니다. 범용 마이크로프로세서들의 성능 개선이 눈에 띄게 둔화된 반면, GPU는 끊임없이 발전을지속해 왔습니다. 2009년을 살펴 보면, 최고 부동 소수 계산 처리량에 대한 다수 코어 GPU와 멀티코어 CPU 간 비율은 약 10대 1입니다. 이러한 속도가 반드시 도달할 수 있는 어플리케이션 속도는 아니며 단순히 실행 리소스가 이 칩들에서 잠재적으로 지원 가능한 속도입니다: 2009년에 1 테라플롭스 (1000 기가 플롭스) 대 100 기가 플롭스였습니다.
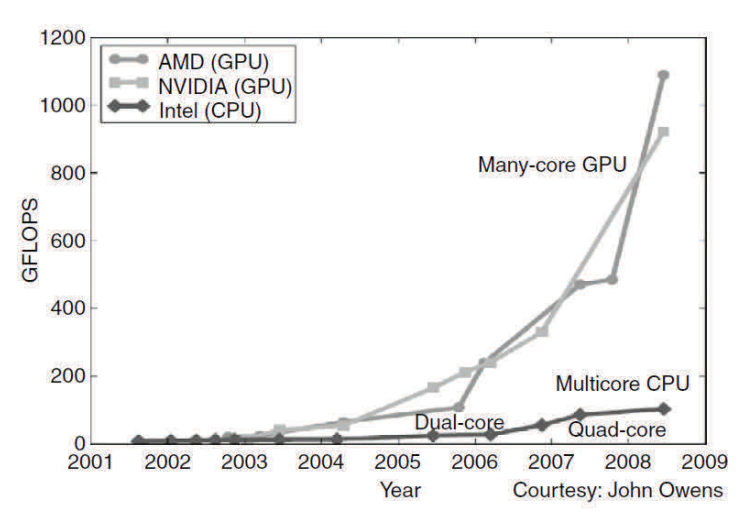
병렬과 순차적 실행 간의 이러한 큰 간극은 괄목할 만한 "전기적 포텐셜" 증강과 비견됩니다. 현재까지 이렇게 큰 성능 차이로 인해 많은 어플리케이션 개발자들이 개발한 소프트웨어의 계산량이 많이 요구되는 부분을 GPU로 이동시키게 되었습니다. 당연히 이처럼 계산량이 많이 요구되는 부분이 병렬 프로그래밍의 일차적 목표입니다. 즉, 할 일이 많을 수록 협동적인 병렬 계산자들 간에 업무를 분담하는 기회는 늘어나게 됩니다.
다수 코어 GPU와 범용 멀티코어 CPU 간에 이토록 큰 간극이 생기는지 의문이 생길 수 있습니다. 이에 대한 해답은 두 가지 프로세서 간에 기본적 설계 철학의 차이에 있습니다. 이는 그림 1.2에 설명되어 있습니다. CPU의 설계는 순차적 코드 성능에 최적화 되어 있습니다. CPU는 순차적 실행의 외형을 유지하면서 병렬 또는 순차적 방식에서 벗어나 실행하기 위해 단일 스레드 실행으로 명령을 수행할 수 있는 정돈된 제어 논리를 이용합니다. 보다 중요한 것은, 거대하고 복잡한 어플리케이션의 명령 및 데이터 접근 레이턴시(잠복기, latency)를 줄일 수 있도록 큰 캐시 메모리가 제공됩니다는 점입니다. 제어 논리나 캐시 메모리 중 어떠한 것도 최대 계산 속도에는 영향을 주지 않습니다. 2009년을 살펴보면, 새로운 범용 멀티 코어 마이크로프로세서가 강력한 순차적 코드 성능을 위해 설계된 네 개의 큰 프로세서 코어를 갖고 있는 것을 알 수 있습니다.
메모리 대역폭(bandwidth)은 또 다른 중요한 이슈입니다. 그래픽스 칩은 대략 현재 CPU 칩의 대역폭의 10배 정도로 운용되어 왔습니다. 2006년 후반, GeForce 8800 GTX (또는 단순히 G80)은 초당 85 기가바이트 (GB/s) 정도로 데이터를 이동할 수 있습니다. 프레임 버퍼 요구 사항과 완화된 메모리 모델 - 다양한 시스템 소프테웨어, 어플리케이션, 입력/출력(IO) 디바이스가 작업을 위한 메모리 접근을 시도하는 방법 - 로 인해 범용 프로세서들은 메모리 대역폭 증가를 더욱 어렵게 만드는 레거시 운영 체제, 어플리케이션, I/O 디바이스로부터 요구 사항을 만족시켜야만 합니다. 이와는 대조적으로, 보다 단순한 메모리 모델과 보다 적은 레거시 제약조건으로 GPU 설계자들은 보다 쉽게 더 크게 메모리 대역폭을 확장할 수 있습니다. 보다 최근의 NVIDIA GT200 칩은 약 150 GB/s를 지원합니다. 마이크로프로세서 시스템 메모리 대역폭은 아마도 최소 3년 내에는 50 GB/s를 넘지 못할 것입니다. 따라서 CPU는 얼마간은 메모리 대역폭 측면에서 약점을 면치 못하게 될 것입니다.
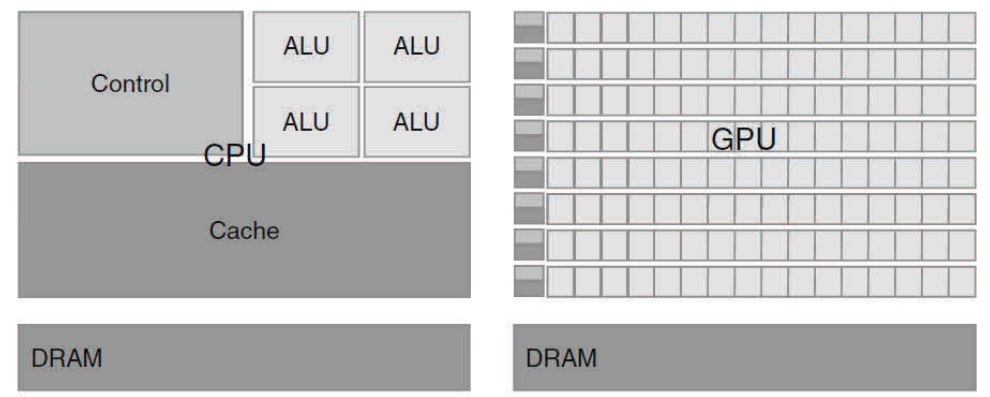
GPU의 설계 철학은 급속도로 성장하는 비디오 게임 산업에 의해 형성되었습니다. 비디오 게임 산업은 게임을 보다 발전시키기 위해 비디오 프레임 당 어마어마한 부동소수 계산을 수행하기 위한 능력 향상을 위한 엄청난 경제적 압박을 가해 왔습니다. 이러한 요구는 GPU 업자들에게 부동 소수 계산에만 치중하도록 하는 칩 영역과 파워 비용을 최대화하는 방안을 강구하도록 하였습니다. 오늘날까지 우수한 솔루션은 막대한 수의 스레드로 계산량 처리를 최적화하는 것입니다. 하드웨어는 이들 중 일부가 긴 레이턴시의 메모리 접근을 기다리는 동안 많은 수의 실행 스레드가 다른 할 일을 찾도록 하는 것입니다. 이렇게 함으로써 각 실행 스레드에 필요한 제어 논리를 최소화 합니다. 이러한 어플리케이션의 대역폭요구량을 제어할 수 있도록 작은 캐시 메모리를 제공하여 동일한 메모리 데이터에 접근하는 다중의 스레드가 모두 DRAM에 접근할 필요가 없는 것입니다. 결과적으로, 보다 많은 칩 영역이 부동 소수 계산에 집중할 수 있습니다.
GPU가 수치 계산 엔진으로 설계되었습니다는 점과 어떤 부분에 있어서는 CPU 보다 좋은 성능을 내지 못할 수도 있습니다는 점을 간과해서는 안 됩니다. 따라서 대부분의 어플리케이션은 CPU와 GPU 모두 사용합니다. 즉, CPU는 순차적인 부분을 수행하고 GPU는 계산량이 많이 요구되는 부분을 담당하는 것입니다. 이것이 바로 CUDA(Compute Unified Device Architecture)나 OpenCL 프로그래밍 모델이 어플리케이션의조인트 CPU/GPU 실행을 지원하도록 설계된 이유입니다.
또한 중요한 것은, 어플리케이션 개발자가 어플리케이션 구동을 위한 프로세서를 선택할 때 성능이 유일한 결정 사항은 아니라는 것입니다. 오히려 다른 요인들이 훨씬 더중요할 수 있습니다. 우선적으로 고려할 것은, 선택한 프로세서가 시장에서 매우 큰 점유율을 차지해야 합니다는 것입니다. 이는 프로세서의 설치 기반으로 일컫습니다. 이유는 간단합니다. 소프트웨어 개발 비용은 고객들의 수로 정당화 됩니다. 협소한 시장 점유의 프로세서는 고객 수가 많지 않습니다. 이것이 범용 마이크로프로세서와 비교했을 때 전통적인 병렬 계산 시스템이 무시되어 온 근본적인 이유였습니다. 정부 또는 대기업이 투자한 소수의 엘리트 어플리케이션만이 이러한 전통적 병렬 계산 시스템 기반에서 성공적으로 개발되어 왔습니다. 이는 다수 코어 GPU의 출현과 함께 인식 변화를 가져 왔습니다. PC 시장에서의 대중화에 힘입어, 수억개의 GPU가 팔렸습니다다. 모든 PC가 GPU를 포함하고 있습니다해도 과언이 아닙니다. G80 프로세서와 이것의 계승자들은 오늘날까지 2억개 이상이 시장에 나왔습니다. 이것이 거대한 병렬 게산이 거대 시장 상품으로 가능해진 첫 단추입니다. 이러한 거대 시장의 출현은 개발자들에게 GPU의 경제적 매력을 제공하였습니다.
또 다른 중요한 결정 요인은 실질적인 형성 요인과 쉬운 접근성입니다. 2006년까지, 병렬 처리 소프트웨어 어플리케이션은 보통 데이터 센터 서버 혹은 정부나 기업체의 클러스터에서 운용되었지만, 이러한 실행 환경은 어플리케이션 사용을 제약하는 결과를 초래했습니다. 예를 들면 의학 영상과 같은 어플리케이션에서 64 노드 클러스터 머쉰을 기반으로 하는 논문을 게재하기에는 적합하지만 실제 자기 공명 영상 (Magnetic Resonance Imaging, MRI) 머쉰 임상 어플리케이션은 모두 PC와 특별한 하드웨어 가속기의 조합으로 된 장치를 기반으로 합니다. 단순한 이유로 GE, Siemens와 같은 제조업자들은 임상 설정을 위한 클러스터 랙(rack)을 갖는 MRI를 팔 수는 없지만 학교와 같은 곳에는 이것이 일반적이기 때문입니다. 사실 상 세계 보건 기구 (National Institutes of Health, NIH)는 얼마 후 병렬 프로그래밍 프로젝트에 대한 자금 지원을 거부했습니다. 이들은 거대한 클러스터 기반의 머쉰이 임상 설정에 적합하지 않기 때문에 병렬 소프트웨어의 효과가 미미합니다고 판단하였습니다. 오늘날, GE는 GPU를 장착한 MRI 제품을 생산하고 있으면 NIH는 GPU 계산을 응용한 연구에 자금을 지원하고 있습니다.
그러나 수치 계산 어플리케이션을 실행하는데 있어 다른 중요한 고려사항은 전기 및 전자공학 협회 (Institute of Electrical and Electronics Engineers, IEEE) 부동 소수표준의 지원입니다. 표준은 서로 다른 업체에서 생산한 프로세서에 관계없이 결과를 예측할 수 있는 도구입니다. IEEE 부동 소수 표준에 대한 지원이 초기 GPU에서는 그리 막강하지는 않았으나, G80이 소개된 후의 GPU세대에서는 막강해졌습니다. IEEE 부동 소수 표준에 대한 GPU 지원은 CPU의 그것과 견줄만합니다. 오늘날 주요 나머지 이슈는 GPU의 부동 소수 계산 유닛(unit)이 기본적으로 단일 정밀도(single precision)이라는 것입니다. 실제로 이중 정밀도(double precision) 부동 소수를 요하는 어플리케이션은 GPU 실행에 적합하지 않았습니다. 그러나, 이것은 최근 GPU와 함께 변화를 겪었으며, 최근 GPU의 이중 정밀도 실행 속도는 단일 정밀도의 연산속도에 근접하였습니다. 이 수준은 하이엔드(highend) CPU 코어의 처리 속도 수준입니다. 이로써 GPU가 훨씬 더 큰 계산 어플리케이션에 적합해 졌습니다.
2006년까지, 그래픽스 칩은 사용하기 어려웠습니다. 왜냐하면 프로그래머들이 프로세서 코어에 접근하기 위해 그래픽 어플리케이션 프로그래밍 인터페이스(Application Programming Interface, API) 함수 또는 이와 대등한 것을 사용해야만 했기 때문입니다. 이러한 API는 OpenGL이나 Direct3D와 같은 기술이 이러한 칩 계산에 필요합니다. 이 기술은 GPGPU라고 불렸으며 그래픽스 처리 장치를 이용한 범용 프로그래밍(General Purpose Graphics Processing Unit, GPGPU)의 약자입니다. 보다 높은 수준의 프로그래밍 환경에서도 API는 여전히 근본적인 코드를 제약하고 있습니다. 이러한 API들은 실제 칩에 대해 작성하는 어플리케이션의 종류를 제약하고 있습니다. 이것이 단지 극소수의 사람들만이 이러한 칩을 이용하기위해 필요한 기술을 익힐 수 있었던 이유입니다.
결과적으로 대중적인 프로그래밍 현상으로 발전하지 못했습니다.그러함에도 불구하고 이 기술은 몇몇의 영웅적인 노력과 뛰어난 결과를 불러 일으키기에 충분했습니다. CUDA와 OpenCL의 등장으로 모든 것이 변하였습니다. NVIDIA는 병렬 프로그래밍이 용이하도록 실리콘 영역에 실제적으로 전념하였기에 소프트웨어 자체만의 변화를 가져온것은 아니었습니다. 칩에 하드웨어가 추가되었습니다. 병렬 계산을 위한 G80과 이들의 계승 칩에 있어 CUDA프로그램은 더이상 그래픽스 인터페이스가 아닙니다. 대신 실리콘 칩 상의 새로운 범용 병렬 프로그래밍 인터페이스는 CUDA 프로그램의 요구에 대응하고 있습니다. 더욱이 다른 모든 소프트웨어 레이어로 재구성되는 것이 아닌 우리에게 익숙한 C/C++ 프로그래밍 툴을 지원하고 있습니다.
1.2. 현대 GPU의 구조
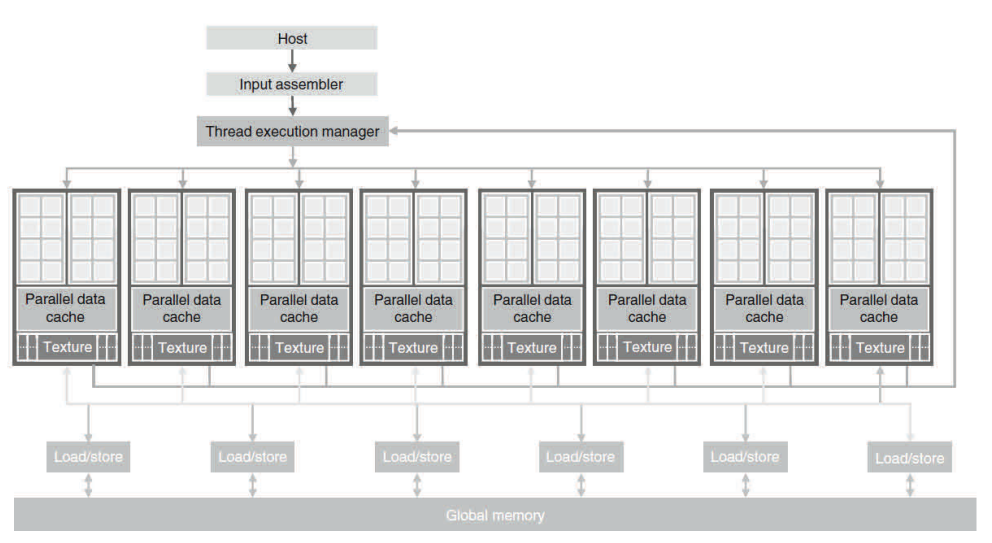
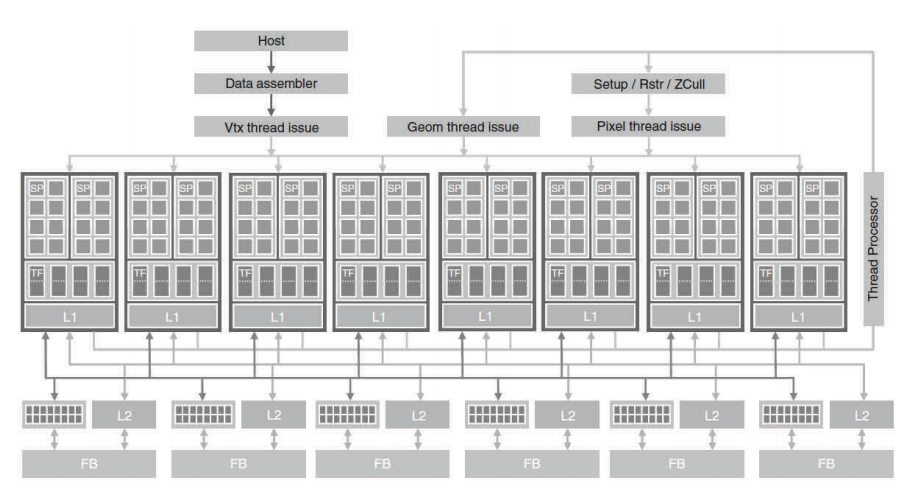
그림 1.3은 일반적인 GPU의 구조를 보여 줍니다. GPU는 고수준의 스레드 스트리밍 멀티프로세서(Streaming Multiprocessor, 이하 SM)의 어레이(array)로 구성됩니다. 그림 1.3에서 두 개의 SM은 하나의빌딩 블럭을 구성합니다. 그러나 빌딩 블럭 내 SM의 개수는 GPU의 각 세대마다 서로 다릅니다. 또한 그림 1.3의 각 SM은 제어 로직과 명령 캐시를 공유하는 수많은 스트리밍 프로세서(Streaming Processor, 이하 SP)를 갖습니다. 현재 각 GPU는 그림 1.3의 글로벌 메모리라고 하는 최대 4기가바이트의 그래픽스 이중 데이터율(Graphics Double Data Rate, 이하 GDDR) DRAM을 장착하고 있습니다. GDDR DRAM은 CPU 마더보드의 시스템 DRAM과는 차이가 있습니다.즉 GDDR DRAM은 기본적으로 그래픽스에 사용되는 프레임 버퍼입니다. 그래픽스 어플리케이션은 비디오 이미지, 3D 렌더링 텍스쳐 정보를 가지고 있으나 계산을 위해 일반적인 시스템 메모리보다 레이턴시가 다소 길지만 매우 높은 대역폭, 오프칩 메모리로서의 기능을 갖습니다.
CUDA 아키덱쳐가 소개된 G80은 86.4 GB/s의 메모리 대역폭, CPU와의 통신을 위한 8-GB/s의 통신대역폭을 가졌습니다. CUDA 어플리케이션은 4 GB/s로 시스템 메모리로부터 데이터를 전달할 수 있고 8 GB/s로 시스템 메모리로 데이터를 업로드 할 수 있습니다. 전부 합하여 전체 8 GB/s입니다. 통신 대역폭은 메모리 대역폭보다 훨씬 작으며 제한이 있어 보입니다. 그러나, PCI Express 대역폭은 시스템 메모리에 대한 CPU 전면 부스 대역폭과 견줄만하며, 따라서 실제로는 제한적이지는 않습니다. 또한 통신 대역폭은 앞으로 시스템 메모리의 CPU 부스 대역폭의 발전에 따라 함께 발전할 것으로 예상됩니다.
고병렬 G80 칩은 128개의 SP를 갖습니다(각각 8개의 SP를 갖는 16 SM). 각 SP는 하나의 MAD(Multiply-Add)를 가지며 추가로 mutiply 유닛을 갖습니다. 128 SP는 전체 500 기가플롭스가 넘는다. 게다가 특수 함수 유닛(Special Function Unit, 이하 SFU)는 Transcedental 함수 뿐만 아니라 제곱근(Square Root, SQRT)과 같은 부동 소수 함수를 수행합니다. 240개의 SP를 갖는 GT200은 1 테라플롭스를 초과합니다. 각 SP는 매우 많은 스레드를 실행하며 어플리케이션 당 수천개의 스레드가 실행됩니다. 훌륭한 어플리케이션은 통상 동시에 칩 상의 5000 - 12,000개의 스레드를 동작시킵니다. 동시 멀티스레드를 사용해 본 경험이 있는 개발자들은 Intel CPU가 코어 당 컴퓨터 모델에 따라 2개 또는 4개의 스레드가 실행됩니다는 사실을 알게 될 것입니다. G80 칩은 SM 당 최대 768개의 스레드를 지원하며 이 칩에 대하여 전부 합하여 12,000개 정도의 스레드를 갖습니다. 보다 최근의 GT200은 SM 당 1024개의 스레드를 지원하며 이 칩에 있어 최대30,000개의 스레드를 지원합니다. 따라서 GPU 하드웨어를 지원하는 병렬 수준은 급속도로 증가하고 있습니다. 따라서 GPU 병렬 계산 어플리케이션 개발 시 이러한 병렬 수준을 고려하는 것이 매우 중요합니다.
1.3. 고수준의 병렬 계산을 하는 이유?
고병렬 프로그래밍(Massively Parallel Programming)을 하는 주목적은 미래의 하드웨어 세대가요구하는 고속의 어플리케이션의 개발입니다. 혹자는 어플리케이션이 어째서 속도의 증가를 끊임없이 요구하는지 의아해 할 것입니다. 오늘날 우리가 사용하고 있는 많은 어플리케이션들은 충분히 빠르게 동작하고 있는지도 모릅니다. GPU에서의 훌륭한 프로그래밍이란 순차적 실행 보다 100배 이상 빠른 속도를 달성해 내는 것입니다. 만약 어플리케이션이 데이터 병렬화(Data Parallelism)이라는 것을 포함합니다면 단 몇 시간의 작업으로 10배 빠른 성능을 달성할 수 있을 것입니다.
오늘날 이미 전 세계에 무수히 많은 계산 어플리케이션이 존재하지만 미래의 대중적 어플리케이션 시장에는 현재 우리가 수퍼컴퓨팅 또는 수퍼어플리케이션이라고 부르는 어플리케이션들이 등장할 것입니다. 예를 들면 생물학 연구 분야는 점점 더 분자 수준으로 이동하고 있습니다. 이는 광학이나 전자 실험 도구에 의존했지만 이러한 도구로도 분자 수준의 관찰을 하는 데에는한계가 있었던 분야입니다. 이러한 한계는 전통적 실험 도구로 설정된 경계 조건을 이용하여 기본이 되는 분자 운동을 시뮬레이션 하는 계산 모델을 통해 효과적으로 극복할 수 있습니다. 시뮬레이션으로부터 보다 자세한 측량을 할 수 있고 전통적 실험 방법만으로는 불가능했던 더욱 많은 가설을 검증할 수 있을 것입니다. 이러한 시뮬레이션은 모델링 될 수 있는 생물학 시스템의 규모와 합리적인 반응 시간 내에 시뮬레이션 될 수 있는 반응 시간 길이의 측면에서 볼 때 예측 가능한 미래에서 분명 증가하는 계산 속도의 이득을 계속적으로 얻을 수 있을 것입니다. 이러한 향상은 과학과 약학에서 막대한 영향을 미칠 것입니다.
비디오 및 오디오 코딩과 같은 어플리케이션에 대해 HDTV와 예전 NTSC 방식의 텔레비전을 비교해 보겠습니다. 일단 우리가 HDTV가 제공하는 고화질을 경험합니다면 이전 기술로 되돌아가기 힘들 것입니다. 그러나 HDTV에 필요한 모든 프로세스를 생각해 보겠습니다. 이것은 3D 이미지 및시각화와 같은 병렬 처리를 요합니다. 미래에는 텔레비전에 시각 합성 및 저해상도 비디오의 고해상도 디스플레이와 같은 새로운 기능이 요구될 것입니다.
보다 강력한 계산 속도가 제공하는 장점 중 한 가지는 보다 뛰어난 사용자 인터페이스입니다. Apple의 iPhone을 생각해 보라. 사용자는 다른 휴대 장치와 비교했을 때 iPhone의 스크린 크기가 작음에도 불구하고 터치 스크린의 보다 자연스러운 인터페이스를 즐깁니다. 의심할 여지 없이 이러한 장치의 미래 버전은 고성능 계산을 요하는 보다 고해상도, 3차원 시각, 음성 및 컴퓨터 비전 기반 인터페이스와 연동될 것입니다.
소비자 전자 게임 분야에서도 발전 방향은 유사합니다. 오늘날 게임에서 차를 운전합니다고 생각해 보겠습니다. 게임분야에서도 발전 방향은 유사합니다. 오늘날 게임에서 차를 운전합니다고 생각해 보겠습니다. 게임은 사실 단순히 미리 셋팅된 씬입니다. 만약 여러분의 차가 장애물과 충돌합니다 하더라도 차의 코스는 바뀌지 않습니다. 게임 스코어만 변합니다. 자동차 휠은 구부러지거나 손상되지 않으며 자동차 휠이 충돌하거나 휠을 잃어버린다 해도 운전하기가 어려워 지지도 않습니다. 고성능 계산으로 게임은 미리 설정된 씬 대신 동역학 시뮬레이션을 기반으로 할 수 있습니다 - 사고는 휠에 손상을 가할 수 있으며 여러분의 드라이빙 경험은 보다 사실적이 될 것입니다. 물리 효과의 사실적 모델링과 시뮬레이션은 엄청난 양의 계산 성능을 요구하는 것으로 알려져 있습니다.
우리가 언급한 모든 새로운 어플리케이션들은 막대한 양의 데이터 처리로 다양한 방식과 다양한 수준으로 현 세계를 시뮬레이션하고 있습니다. 또한 이토록 어마어마한 양의 데이터와 엄청난 계산은 비록 어떤 면에서는 현실과 타협합니다 하더라도 데이터의 병렬처리로써만 이뤄질 수 있습니다. 이러한 기술은 통상적인 개발을 하던 개발자들에게 익숙합니다. 따라서, 병렬화의 다양한 양상이 존재하지만 프로그래밍 모델이 병렬 실행을 방해해서는 안 되며 데이터 교환은 적절히 다루어져야 합니다. CUDA는 병렬 실행을 지원하는 하드웨어 모델의 프로그래밍을 포함합니다.
이러한 수퍼 어플리케이션을 병렬화하여 얼마나 큰 속도 증가를 기대할 수 있을까요? 이것은 어플리케이션의 병렬화 가능한 부분과 관련 있습니다. 병렬화 가능한 부분에 시간을 할애하는 비율이 30%라면 병렬화 비율의 100배 속도 향상은 실행 시간을 29.7% 만큼 낮춘다.전체 어플리케이션의 속도 향상은 단지 1.4배 정도입니다. 사실 병렬 비율에서 무한량의 속도 증가를 합니다 하더라도 실행 시간 단축은 30%를 넘치 못합니다. 즉 1.43배의 이상의 속도 증가는 불가능합니다. 반면에 만약 실행 시간의 99%가 병렬 부분이라면 100배의 속도 향상은 원래의 1.99%만큼 어플리케이션 실행 시간을 단축시킵니다. 이는 전체 어플리케이션을 50배 속도 향상을 가져다 줍니다. 따라서 효과적인 실행 속도 향상을 위해 어플리케이션들은 대부분의 실행 시간을 고병렬 프로세서에 할애합니다는 사실은 중요합니다. 연구자들은 몇몇 어플리케이션에서 100 이상의 속도 향상을 달성했습니다. 그러나, 이는 알고리즘이 병렬 실행으로 실행 시간을 99.9% 이상 단축시키는 막대한 최적화와 튜닝이 이루어진 후에 가능합니다. 일반적으로 어플리케이션의 단순한 병렬화는 메모리 (DRAM) 대역폭을 포화시키며 결과적으로 10배 가량의 속도 향상을 가져다 줍니다. 트릭은 메모리 대역폭에 대한 제한을 어떻게 회피하느냐에 관한 것이며, 이는 특수한 GPU 온칩 메모리를 이용하여 효과적으로 DRAM으로의 접근 개수를 줄이기 위해 다양한 방법 중 하나를 포함합니다.
그러나, 제한적인 온칩 메모리 용량과 같은 제약을 회피하기위한 코드 최적화에 대한 좀 더 많은 연구가 이루어져야 할 것입니다. CPU 실행을 통한 속도 향상 수준은 어플리케이션에 대한 CPU의 적합성과 관련이 있습니다는 사실을 명심하기 바랍니다. 몇몇 어플리케이션들에서는 CPU가 매우 잘 실행되는데, GPU를 이용한 성능 향상이 오히려 어려운 경우도 있습니다. 대부분의 어플리케이션들은 CPU로 실행하는 것이 나은 성능을 보이는 경우가 많다. 따라서, CPU에게도 공정한 기회를 부여해야 하며 GPU가 CPU를 지원하는 형식으로 코드를 구성하는 것이 바람직합니다. 따라서 이상적인 이종 병렬 계산 방식은 CPU와 GPU 시스템을 적절히 조합하는 것입니다. 이것이 바로 CUDA 프로그래밍 모델이 지향하는 바입니다.
그림 1.4는 통상적인 어플리케이션의 핵심 부분을 보여 주고 있습니다. 실제 어플리케이션의 코드의 대부분은 순차적인 경향을 지닙니다. 이러한 점은 함정이 되는 부분입니다. 이러한 순차적 부분에 병렬 컴퓨팅 기술을 적용하려고 하는 것은 함정에 빠지는 것과도 같습니다. 결코 좋은 생각이 아니라는 것입니다. 이러한 부분은 병렬화하기 매우 어렵습니다. CPU는 이러한 부분에 매우 적합합니다. 다행인 것은 순차적 부분이 코드의 대부분을 차지함에도 불구하고 수퍼어플리케이션의 실행 시간 중 작은 부분만을 차지하고 있습니다는 것입니다.
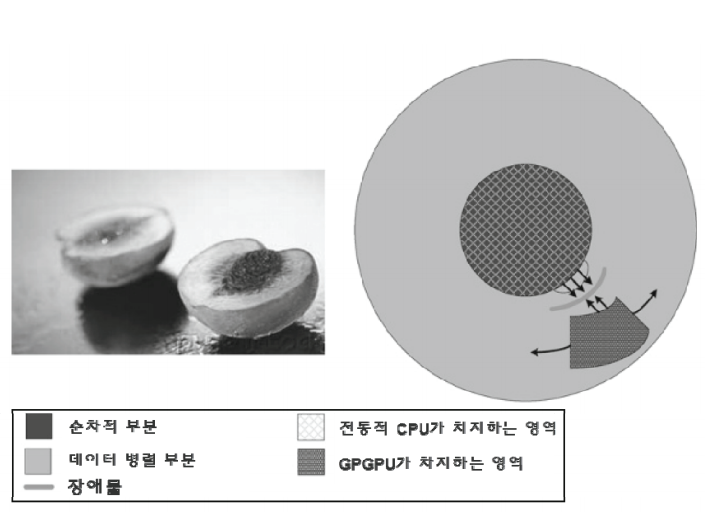
이제 계산이 요구되는 또다른 핵심부분에 대해 언급할 차례입니다. 이러한 부분은 몇몇 초기 그래픽스 어플리케이션처럼 병렬화하기 쉽습니다. 예를 들어 오늘날 대부분의 의학 이미징 어플리케이션은 아직도 마이크로프로세서 클러스터와 특수목적 하드웨어의 조합으로 구성됩니다. GPU의 비용과 크기에 대한 이득은 이러한 어플리케이션의 품질을 효과적으로 향상시킵니다. 그림 1.4에서 설명한 바와 같이 초기 GPGPU는 매우 작은 부분만을 담당하였는데, 이는 이 작은 부분이 이후 10년 간 새로운 어플리케이션의 작지만 가장 흥미로운 부분입니다. 이처럼 점점 증가해 가는 어플리케이션의 흥미로운 부분을 담당하기 위해 CUDA 프로그래밍 모델이 설계되었습니다.
1.4. 병렬 프로그래밍 언어와 모델
지난 몇 십년간 많은 병렬 프로그래밍 언어와 모델이 제안되어 왔습니다. 가장 널리 사용되는 것 중 하나가 스케일러블(scalable) 클러스터 컴퓨팅을 위한 메시지 전달 인터페이스(Message Passing Interface, 이하 MPI)와 공유 메모리 멀티프로세서 시스템을 위한 OpenMP™입니다. MPI는 클러스터 내의 계산 노드들이 메모리를 공유하지 않는 모델입니다. 즉, 모든 공유 데이터 및 상호작용이명시적 메시지 전달을 통해 이뤄져야합니다. MPI는 고성능 과학 계산 분야에서 성공적이라는 평가를 받습니다. MPI로 작성된 어플리케이션은 100,000개 이상의 노드들을 갖는 클러스터 컴퓨팅 시스템 상에서 성공적으로 실행됩니다고 알려져 있습니다. 그러나 계산 노드들 간에 공유 메모리가 부족으로 인해 MPI로 어플리케이션을 포팅하는데 필요한 노력의 양은 엄청날 수 있습니다. 반면에 CUDA는 이러한 어려움을 해소하기 위해 GPU 내의 병렬 실행을 위한 공유 메모리를 제공합니다. CPU와 GPU 간 통신에 있어 CUDA는 현재 CPU-GPU 간 매우 제한된 공유 메모리를 제공합니다. 프로그래머들은 "일방적" 메시지 전달과 유사한 방식으로 CPU-GPU 간 데이터 전달 작업을 관리할 필요가 있습니다. "일방적" 메시지 전달이 없던 시절 이는 MPI의 최대 약점으로 꼽히곤 했습니다.
OpenMP가 공유 메모리를 지원하기 때문에 CUDA 프로그래밍과의 장점을 나란히하고 있습니다. 그러나, 스레드 관리 오버헤드와 캐시 일관 하드웨어 요구로 인해 수백개의 계산 노드로 개수를 늘릴 수 없었습니다. CUDA는 간단하고 낮는 오버헤드 스레드 관리와 캐시 일관 하드웨어 요구가 없다는 장점으로 보다 높은 확장성을 가지고 있습니다. 그러나 CUDA는 이러한 확장성 상충관계로 인해 OpenMP 만큼 넓은 어플리케이션 범위를 지원하지 않습니다. 반면 많은 수퍼어플리케이션들은 CUDA의 간단한 스레드 관리 모델을 도입하여 확장성과 성능 향상을 꾀하고 있습니다.
OpenMP 컴파일러가 병렬 실행 관리의 자동화가 보다 진보되었음에도 불구하고 프로그래머가 병렬 코드 구조를 관리한다는 면에서 CUDA의 구조는 MPI와 OpenMP와 유사합니다. 현재 진행 중인 많은 연구 과제는 CUDA 툴 체인에 대한 병렬화 관리의 자동화와 성능 최적화를목표로 하고 있습니다. MPI와 OpenMP 개발 경험자들은 CUDA가 배우기 쉽다는 것을 알게 될 것입니다. 기본적으로 대부분의 성능 최적화 기술은 이러한 모델들에 있어 공통적인 부분입니다.
보다 최근에 Apple, Intel, AMD/ATI, NVIDIA등과 같은 여러 굵직한 산업계 거목들은 OpenCL™이라 불리우는 표준 프로그래밍 모델을 함께 개발하고 있습니다. CUDA와 유사하게 OpenCL 프로그래밍 모델은 언어 확성성과 런타임 API를 정의하여 프러그래머들이 고병렬 프로세서에 있어 병렬화와 데이터 전달 관리를 할 수 있도록 배려하고 있습니다. OpenCL을 이용하여 개발된 어플리케이션들이 OpenCL 언어 확장과 API를 지원하는 모든 프로세서 상의 수정할 필요 없이 작동할 수 있다는 점에서 표준화 된 프로그래밍 모델입니다.
현재 OpenCL은 아직 초기 단계입니다. OpenCL의 프로그래밍 구조 수준은 여전히 CUDA 보다 저수준이며 사용하기에도 더 번거로운 면이 있습니다. 또한 OpenCL로 구현된 어플리케이션 속도는 동일한 플랫폼에서 구현된 CUDA 보다 훨씬 떨어진다. 고병렬 프로세서 프로그래밍의 핵심은 속도이기 때문에 앞으로도 얼마간은 고병렬 프로세서를 사용하고자 하는 프로그래머들은 CUDA 계속사용할 것으로 기대됩니다. 결국 OpenCL과 CUDA에 모두 익숙한 개발자들은 이 둘 사이에 핵심적인 특징은 매우 유사합니다는 것을 알고 있습니다. 즉, CUDA 프로그래머는 최소한의 노력으로 OpenCL 프로그래밍을 배울 수 있을 것입니다.
2. GPU 역사
1999년 NVIDIA가 처음으로 발명한 그래픽 처리 장치(GPU)는 지금까지 가장 널리 알려진 병렬 프로세서입니다. 실세계와 같은 그래픽스 표현을 위해 GPU는 전에 없던 부동 소수 성능과 프로그램 가능성을 갖춘 프로세서로 진화를 거듭했습니다. 오늘날의 GPU는 CPU의 연산 능력과 메모리 대역폭을 능가하며 다양한 데이터 병렬 어플리케이션을 가속하기 위한 이상적인 프로세서로 발전하고 있습니다.
2003년 이후 비그래픽 어플리케이션에 대한 GPU 사용을 위한 노력이 있어 왔습니다. DirectX, OpenGL,Cg 등의 고수준 셰이딩 언어를 사용하여 다양한 데이터 병렬 알고리즘이 GPU로 포팅되어 왔습니다. 단백질 폴딩(folding), 스톡 옵션 가격, SQL 쿼리, MRI 재구성 등의 문제들을 통해 괄목할 만한 GPU의 성능 개선을 이루어냈습니다. 범용 계산을 위한 그래픽스 API를 사용하던 이러한 초기 노력은 GPGPU 프로그램이 알려졌습니다.
GPGPU 모델이 뛰어난 속도를 보임에도 불구하고한편으로 여러가지 문제점을 드러내기도 했습니다. 우선 프로그래머에게 그래픽스 API와 GPU 아키텍쳐의 자세한 지식이 요구되었습니다. 둘째, 문제들은 정점 좌표, 텍스쳐 및 셰이더 프로그램으로 표현되어야 했으며 이는 문제를 매우 복잡하게 만들었습니다. 셋째, 랜덤 메모리 읽기 및 쓰기와 같은 기본 프로그래밍 특성이 지원 되지 않았으며 이는 프로그래밍 모델에 많은 한계를 부여했습니다. 마지막으로 이중 정밀도(Double Precision) 지원의 부족으로 몇몇 과학 응용 분야에서는 GPU를 실행할 수가 없었습니다.
이러한 문제를 해결하기 위해 NVIDIA는 두 가지 핵심 기술을 소개하였습니다 - G80 통합 그래픽스 계산 아키텍쳐 (GeForce 8800, Quadro FX 5600에서 처음 소개되었습니다)와 GPU가 다양한 고수준 프로그래밍언어로 프로그램 가능하도록 한 소프트웨어 및 하드웨어 아키텍쳐인 CUDA가 그것입니다. 이 두 가지 기술은 GPU를 활용하는 새로운 길을 열었습니다. 그래픽스 API를 이용한 그래픽스프로그래밍 대신 프로그래머는 CUDA 확장을 이용해 C 프로그램 작성이 가능해졌으며 범용 고병렬 프로세서를 목표로 할 수 있게 되었습니다. 이러한 GPU 프로그래밍을 "GPU 계산"이라 부르게 되었습니다 - 이는 보다 광범위한 어플리케이션 지원, 보다 넓은 프로그래밍 언어 지원, 초기 "GPGPU" 프로그래밍 모델로부터 완벽한 분리의 신호탄이 되었습니다.
2.1. GPU 역사를 소개하며...
CUDA와 OpenCL 프로그래머들에게 GPU는 C의 확장 언어로 프로그램 된 고병렬 수치 계산 프로그램입니다. 이 프로세서를 사용하기 위해 그래픽 알고리즘이나 용어를 익힐 필요는 없습니다. 그러나, 그래픽 분야로부터 발전된 GPU는 대다수의 계산 패턴에 대한 GPU의 약점 및 강점을 반영합니다. 특히 GPU가 발전해 온 역사를 이해합니다면 현대 프로그래밍 가능한 GPU - 막대한 멀티스레딩, CPU와 비교했을 때 상대적으로 작은 메모리 캐시, 밴드폭 중심의 메모리 인터페이스 설계 - 의 아키텍쳐 설계가 어떻게 발전해 왔는지를 이해하는데 도움이 될 것입니다. 발전해 온 역사를 들여다보면 미래의 계산 장비로서의 GPU의 발전 방향 또한 이해할 수 있을 것입니다.
2.2. 그래픽스 파이프라인의 진화
3차원(3D) 그래픽스 파이프라인 하드웨어는 1980년대 초의 거대한 시스템으로부터 작은 워크스테이션을 거쳐 1990년대 중반과 후반의 PC 가속기로 진화되어 왔습니다.이 기간 동안, 성능을 이끌어 온 그래픽스 서브시스템의 가격은 $50,000에서 $200까지 하락되었습니다. 같은 기간동안, 성능은 초당 5천만 픽셀에서 초당 10억픽셀까지 그리고 초당 100,000개 정점에서 초당 1000만개의 정점까지 처리할 수 있는 정도로 향상되었습니다. 이러한 발전이 반도체 장비의 크기가 끊임없이 축소되어 온 영향이 있겠지만 그래픽스 알고리즘과 현대 GPU의 원천적 하드웨어 성능의 혁신에서 비롯된 것임을 부인할 수 없습니다.
눈에 띄는 그래픽스 하드웨어 성능의 발전은 컴퓨터 어플리케이션 시장의 고품질, 실시간 그래픽스 요구에 따라 가속화 되어 왔습니다. 예를 들어 전자 게임 어플리케이션에서 초당 60 프레임으로 전에 없던 보다 복잡한 씬의 렌더링이 요구될 것입니다. 결론을 말하자면, 30년을 넘는 세월 동안 그래픽스 아키텍쳐는 와이어 프레임 다이어그램을 그리기 위한 간단한 파이프라인에서부터 복잡한 3D 씬의 인터랙티브 이미지 렌더링 능력을 갖춘 여러 개의 병렬 파이프라인들로 진화되어 왔습니다. 동시에 관련된 많은 하드웨어 기능들이 훨씬 더 정교해지고 사용자 프로그램이 가능해졌습니다.
2.1.1. 고정 기능 그래픽스 파이프라인 시대
1908년대 초반에서 1990년대에 이르기까지, 기술을 선도하는 성능 그래픽스 하드웨어는 설정 가능하지만 프로그램은 불가능한 고정 기능 파이프라인이었습니다. 같은 시기에, 메이저 그래픽스 어플리케이션 프로그래밍 인터페이스(API) 라이브러리들은 대중화 되었습니다. API는 어플리케이션이 소프트웨어나 하드웨어 서비스와 기능을 사용할 수 있는 표준화된 소프트웨어의 레이어(가령 라이브러리 함수의 모음)입니다. 예를 들어 API는 게임과 같은 어플리케이션들이 디스플레이 상에 오브젝트를 그리기 위한 그래픽 처리 장치에 명령을 전달하도록 할 수 있습니다. 이러한 API 중 하나가 미디어 기능을 구현하기 위한 Microsoft의 DirectX™입니다. DirectX™의 Direct3D 컴포넌트는 그래픽스 프로세서에 인터페이스 기능을 제공합니다. 또 다른 메이저 API는 OpenGL이며, 이는 다양한 벤더들이 지원하는 오픈 표준 API인 동시에 대중적인 프로페셔널 워크스테이션 어플리케이션입니다. 이러한 고정 기능 그래픽스 파이프라인의 시대는 대략적으로 DirectX™의 첫 일곱 세대에 상응합니다.
그림 2.1은 초기 NVIDIA GeForce GPU의 고정 기능 그래픽스 파이프라인의 예를 보여 주고 있습니다. 호스트 인터페이스는 CPU로부터 그래픽스 명령과 데이터를 받습니다. 명령들은 API 함수를 호출하여 일반적으로 어플리케이션 프로그램에 의해 주어진다. 호스트인터페이스는 호스트 시스템 메모리와 그래픽스 파이프라인 간에 벌크 데이터를 효율적으로 전달하기 위한 특수한 직접 메모리 접근(Direct Memory Access, 이하 DMA) 하드웨어를 포함합니다. 또한 호스트 인터페이스는 명령 실행에 대한 상태 및 결과 데이터를 통신합니다.
파이프라인의 다른 단계를 설명하기에 앞서 일반적으로 폴리곤의 코너라 불리우는 정점이라는 용어를 이해해야 합니다. GeForce 그래픽스 파이프라인은 삼각형을 렌더링하도록 설계되어 있기 때문에 정점은 통상적으로 삼각형의 코너로 일컬어 집니다. 오브젝트의 표면은 삼각형의 집합으로 그려집니다. 삼각형의 크기가 작아질수록 그림의 품질은 향상됩니다. 그림 2.1의 정점 제어 단계는 CPU로부터 파라미터화 된 삼각형 데이터를 받습니다. 이후 정점 제어 단계는 하드웨어가 이해하고 준비된 데이터를 정점 캐시로 보내는 형태로 삼각형 데이터를 변환합니다.
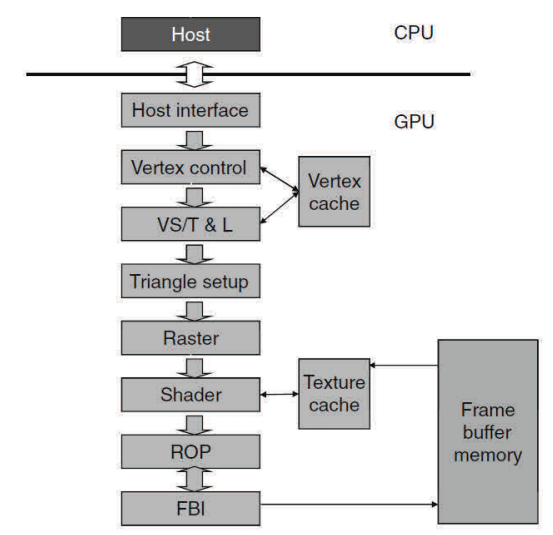
그림 2.1에서 정점 쉐이딩(Vertex Shading), 변환(Transformation), 라이팅(Lighting) (이를 합쳐 VS/T&L이라고도 합니다)은 정점을 변환하고 정점 별 값들(가령 컬러, 노말, 텍스쳐 좌표, 탄젠트 등)을 할당합니다. 쉐이딩은 픽셀 셰이더 하드웨어에 의해 수행됩니다. 정점 셰이더는 각 정점에 컬러를 부여할 수 있지만 다음 단계까지 컬러는 삼각 픽셀에 적용되지 않습니다. 삼각형 구성 단계는 컬러와 삼각형이 걸치는 픽셀 간에 다른 정점 별 데이터(텍스쳐 좌표와 같은)에 사용되는 엣지 방정식을 생성합니다. 래스터 단계는 각 삼각형에 어느 픽셀이 포함될 지를 결정합니다. 각 픽셀에 대하여 래스터 단계는 픽셀에 쉐이딩 (페인팅) 될 컬러, 위치, 텍스쳐 위치를 포함하여 픽셀 쉐이딩 필요한 정점 별 값들을 보간합니다.
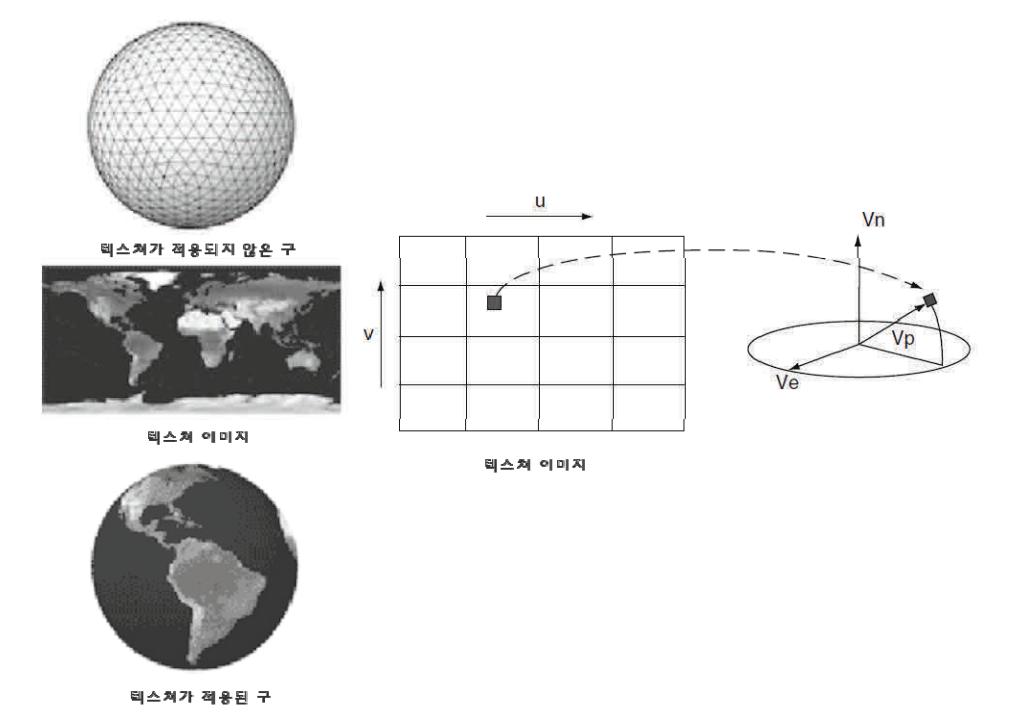
그림 2.1의 셰이더 단계는 각 픽셀의 최종 컬러를 결정합니다. 이는 다양한 기술의 효과의 조합으로 생성될 수 있습니다: 정점 컬러의 보간, 텍스쳐 맵핑, 픽셀 별 라이팅 수학, 반사 등. 렌더링 된 이미지를 보다 사실적으로 표현하는 많은 효과들이 셰이더 단계에 실행됩니다. 그림 2.2는 셰이더 단계 기능 중 하나인 텍스쳐 맵핑을 설명하고 있습니다. 월드 맵 텍스쳐가구 오브젝트에 어떻게 맵핑되는지를 보여 줍니다.
구 오브젝트는 수많은 삼각형의 집합으로 표현됩니다. 셰이더 단계가 구 오브젝트를 표현하는 삼각형 중 하나의 삼각형에 있는 포인트 상에 페인팅 되는 텍스쳐 포인트의 정확한 좌표를 구별하기 위한 단지 작은 수의 좌표 변환 계산을 실행해야 함에도 불구하고, 이미지가 커버하는 순수한 개수의 픽셀들은 셰이더 단계가 각 프레임 마다 매우 많은 수의 좌표 변환 연산을 수행하도록 요구합니다.
그림 2.2의 래스터 변환(Raster Operation, 이하 ROP) 단계는 픽셀에 대한 최종 래스터 변환을 수행합니다. 이는 컬러 래스터 변환을 수행하고 투명 및 안티알리아싱 효과를 위한 겹치는/이웃하는 오브젝트들의 컬러를 혼합합니다. 또한 주어진 시점에서 가시 오브젝트를 결정하여 가려진 픽셀을 무시합니다. 픽셀은 주어진 시점에 따라 다른 오브젝트들로부터 차단된 픽셀이 있을 경우 가려집니다.
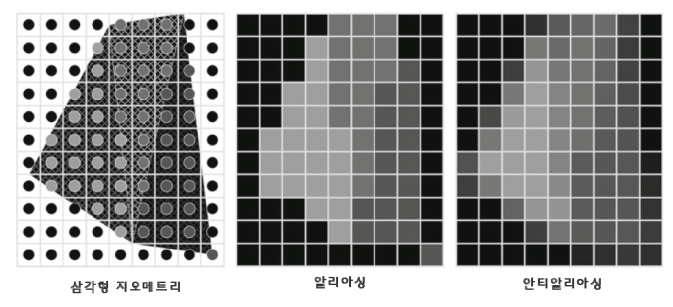
그림 2.3은 ROP 단계에서 수행되는 기능 중 하나인 안티알리아싱을 설명하고 있습니다. 검정 배경의 세 개의 이웃하는 삼각형을 살펴보겠습니다. 알리아싱 되어 있는 출력에서 각 픽셀은 오브젝트 중 하나 또는 배경의 컬러를 가정합니다. 해상도의 제한으로 인해 엣지는 굴곡이 있어 보이며 오브젝트의 모양은 왜곡되어 보입니다. 문제는 다수의 픽셀이 어떤 다른 오브젝트의 영역을 부분적으로 차지하기도 하고 다른 오브젝트나 배경의 일부분을 차지하기도 합니다는 것입니다. 이러한 픽셀들이 오브젝트 중 하나의 오브젝트의 컬러를 가정하게 됩니다면 오브젝트들의 엣지에 왜곡이 생기게 됩니다. 안티알리아싱 연산은 부분적으로 픽셀을 겹치는 모든 오브젝트들과 배경의 컬러로부터 혼합또는 선형적으로 결합된 컬러를 각 픽셀에 부여합니다. 픽셀의 컬러를 결정하는 데 있어 각 오브젝트의 영향은 오브젝트가 겹쳐지는 픽셀의 양과 관련이 있습니다.
그림 2.1의 결국 프레임 버퍼 인터페이스(Frame Buffer Interface, 이하 FBI) 단계는 디스플레이 프레임 버퍼 메모리의 쓰기와 읽기 작업을 관리합니다. 고해상도 디스플레이를 위해서는 프레임 버퍼에 접근에 있어 매우 높은 대역폭이 필요합니다. 이러한 대역폭은 두 가지 전략으로 달성할 수 있습니다. 하나는 그래픽스 파이프라인이 시스템 메모리보다 높은 대역폭을 제공하는 특수 메모리 설계를 이용하는 방법입니다. 다른 하나는, FBI가 다중 메모리 뱅크에 접속하는 다중 메모리 채널을 동시에 관리하는 것입니다. 다중 채널과 특수 메모리 구조를 결합한 대역폭 개선은 동시 다발성 시스템 메모리보다 훨씬 높은 대역폭을 프레임 버퍼에 제공합니다. 이러한 높은 메모리 대역폭은 오늘날까지 꾸준히 이어지고 있으며 현대 GPU 설계의 차별화 된 특징으로 자리잡고 있습니다.
20년 간 하드웨어와 이에 상응하는 API의 각 세대는 그래픽스 파이프라인의 다양한 단계에 점진적인 개선을 가져왔습니다. 각 세대마다 하드웨어 리소스의 추가 및 파이프라인 단계에 설정 가능성을 불어넣었음에도 불구하고, 개발자들의 실력은 날로 향상되고 빌트인(built-in) 고정 기능으로 제공되는 것보다 더 많은 새로운 기능을 요구하고 있습니다. 따라서 다음 단계에서 명확히 요구되는 것은 이러한 그래픽스 파이프라인 단계 중 일부를 프로그래밍 가능한 프로세서가 되도록 하는 것입니다.
2.1.2. 프로그램 가능한 실시간 그래픽스의 진화
2001년 NIVIDA GeForce 3는 진정한 범용 셰이더 프로그래밍 가능성을 달성을 향한 첫 걸음을 내딛였습니다. 셰이더 프로그래밍 가능성은 한때 부동 소수 정점 엔진의 사설 내부 지침서로 사용되었던 것을 어플리케이션 개발자들에게 공개하는 것입니다 (VS/T&L 단계). 이는 Microsoft의 DirectX 8과 OpenGL 정점 셰이더 확장판을 공개하는 것과 같은 맥락입니다. DirectX 9의 시대의 GPU는 픽셀 셰이더 단계로 범용 프로그래밍 가능성과 부동 소수 기능을 확장하고 정점 셰이더 단계에서 텍스쳐에 접근 가능하도록 하였습니다. 2002년에 소개된 ATI Radeon™9700은 DirectX 9과 OpenGL로 프로그램 된 프로그램 가능한 24비트 부동 소수 픽셀 셰이더 프로세서입니다. GeForce FX는 32비트 부동 소수 픽셀 프로세서를 추가하였습니다. 이러한 프로그램 가능한 픽셀 셰이더 프로세서들은 어플리케이션 프로그래머의 추세처럼 다른 단계의 기능을 통합하는 방향이 일반적인 추세의 한 부분이었습니다. GeForce 6800과 7800 시리즈는 정점과 픽셀 프로세싱을 위한 개별 프로세서 설계로 개발되었습니다. XBox 360은 2005년 초기 통합 프로세서를 소개하였습니다. 이는 정점 및 픽셀 셰이더가 동일한 프로세서 상에서 구동하도록 하였습니다.
그래픽스 파이프라인에서 특정 단계는 삼각형 정점의 위치를 변환하거나 픽셀 컬러를 생성하는 등 완전히 독립적인 데이터 상에서 어마어마한 부동 소수 연산을 수행합니다. 이러한 지배적 어플리케이션 특성으로서의 데이터 독립성은 GPU와 CPU에 대한 설계 상정 간의 핵심이 되는 차이점입니다. 1/60초 마다 렌더링 되는 하나의 프레임은 백만 삼각형과 600만 픽셀을 가질 것입니다. 이러한 데이터 독립성을 위해 하드웨어 병렬화를 사용할 수 있는 기회는 무궁무진합니다.
몇몇 그래픽스 파이프라인 단계에서 실행되는 특정 함수들은 렌더링 알고리즘에 따라 다양합니다. 이러한 다양성은 하드웨어 설계자들이 이러한 파이프라인 단계들을 프로그램 할 수 있도록 하였습니다. 두 개의 특별한 단계들이 두드러집니다: 정점 셰이더와 픽셀 셰이더. 정점 셰이더 프로그램은 삼각형 정점들의 위치를 스크린에 맵핑하여 정점들의 위치, 컬러,방향을 변화시킵니다. 통상적으로 정점 셰이더 스레드는 부동 소수 (x, y, z, w) 정점 위치를 읽고 부동 소수 (x, y, z) 스크린 위치를 계산합니다. 기하 셰이더 프로그램은 여러 개의 정점으로 정의된 프리미티브 상에서 작동하며 프리미티브를 변형하거나 추가적인 프리미티브를 생성합니다. 정점 셰이더 프로그램과 기하 셰이더 프로그램은 그래픽스 파이프라인의 정점 셰이더 (VS/T&L) 단계에서 실행됩니다.
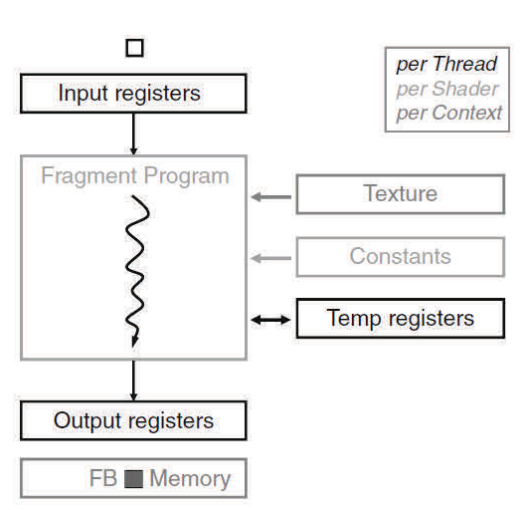
셰이더 프로그램은 픽셀 샘플(x, y) 이미지 위치에 렌더링 된 이미지의 부동 소수 적, 녹, 청, 알파(RGBA) 컬러 기여도를 계산합니다. 이러한 프로그램들은 그래픽스 파이프라인의 셰이더 단계에서 실행됩니다. 그래픽스 셰이더 프로그램의 모든 세 가지 타입에 대해 각 프로그램 인스턴스는 독립적인 데이터로 작동하며 독립적인 결과를 출력하며 아무런 부작용이 없기 때문에 프로그램 인스턴스는 병렬로 실행될 수 있습니다. 이러한 특성은 프로그램 가능한 파이프라인 단계를 고병렬 프로세서로 이동시키는 원동력이 되었습니다.
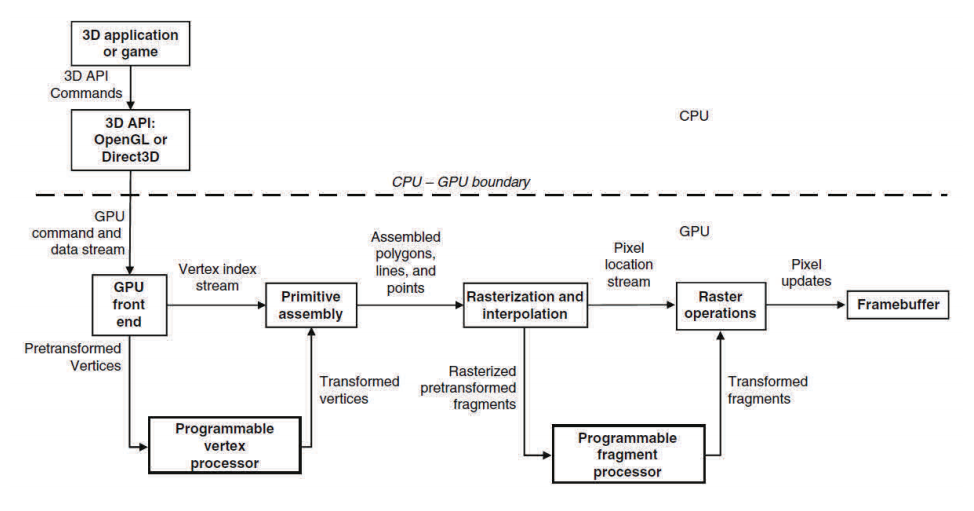
그림 2.4는 정점 프로세서와 프래그먼트(픽셀) 프로세서를 활용하는 프로그램 가능한 파이프라인의 예시를 보이고 있습니다. 프로그램 가능한 정점 프로세서는 정점 셰이더 단계에 할당된 프로그램을 실행하며 프로그램 가능한 프래그먼트 프로세서는 픽셀 셰이더 단계에 할당된 프로그램을 실행합니다. 이러한 프로그램 가능한 파이프라인 단계 사이에는 프로그램 가능한 프로세서 보다 훨씬 더 효율적으로 잘 정의된 작업을 수행하는 몇몇의 고정 기능 단계가 존재합니다. 예를 들어 정점 프로세싱 단계와 픽셀(프래그먼트) 프로세싱 단계 사이에는 래스터라이저(래스터화 및 보간), 즉 어느 픽셀이 각 기하 프리미티브의 경계 안에 놓여 있는지를 정확히 판단하는 복잡한 상태 기계가 존재합니다. 이와 함께 프로그램 가능한 단계와 고정 기능 단계를 혼합하면 렌더링 알고리즘에 대한 사용자 제어와 함께 성능 극대화를 기대할 수 있습니다.
공통적 렌더링 알고리즘은 입력 프리미티브에 대한 싱글 패스를 수행하고 굉장히 일관적인 방식으로 다른 메모리 리소스에 접근합니다. 즉, 이러한 알고리즘은이웃하는 모든 삼각형이나 모든 픽셀과 같이 인접한 메모리 위치를 동시에 접근하는 경향이 있습니다. 결과적으로 이러한 알고리즘들은 메모리 대역폭 활용에 있어 뛰어난 효율성을 보이며 메모리 레이턴시에 그다지 민감하지 않습니다. 보통 제한적으로 계산되는 픽셀 셰이더 작업과 결합하여 이러한 특성들은 GPU를 CPU와는 다른 발전방향으로 안내해 왔습니다. 특히 캐시 메모리로 인해 CPU의 입지가 줄어드는 영역에는 GPU가 부동 소수 데이터경로와 고정 기능 논리로 지배받습니다. GPU 메모리 인터페이스는 레이턴시 보다는 대역폭을 강조합니다(레이턴시가 고병렬 실행에서 은폐되는 것과 마찬가지). 사실 대역폭은 보다 최근의 설계에서 100 GB/s를 초과하는 CPU의 대역폭 보다 몇 배 높습니다.
2.1.3. 통합 그래픽스 및 계산 프로세서
2006년에 소개된 GeForce 8800 GPU는 분리되었던 프로그램 가능한 그래픽스 단계를 일련의 통합 프로세서로 통일하였습니다. 이는 그림 2.5에 잘 나타나 있습니다. 통합 프로세서 어레이(array)는 어레이를 동적으로 정점 쉐이딩, 기하 프로세싱, 픽셀 프로세싱으로분할하였습니다. 이들 세 개의 프로그램 가능한 단계 중 서로 다른 렌더링 알고리즘들은 서로 다른 부하가 걸리기 때문에 이러한 통합은 실행 리소스의 동일한 풀(pool)이 다른 파이프라인 단계에 동적으로 할당되게 하여 더 나은 부하 균형을 이루도록 합니다.
GeForce 8800 하드웨어는 DirectX 10 API 세대에 상응합니다. DirectX 10 세대 즈음에, 정점과 픽셀 셰이더의 기능은 프로그래머에게는 동일한 것이 되었으며 새로운 논리적 단계가 소개 되고 기하 셰이더는 정점 자체 보다는 프리미티브의 모든 정점을 처리할 수 있게 되었습니다. GeForce 8800은 사실상 DirectX10을 염두에 두고 개발되었습니다. 개발자들은 보다 세련된 쉐이딩 알고리즘을 내놓기 시작했고 이로 인해 부동 소수 연산 등에 있어 가능한 셰이더 연산율의 가파른 상승을 불러 일으켰습니다. NVIDIA는 원하는 연산을 수행하기 위한 표준 셀 방식으로 실행해 왔던것들보다 높은 연산 클럭 주파수의 프로세서 설계를 지향해 왔습니다. 높은 클럭 속도 설계는 막대한 공학적 노력이 필요하기 때문에 두 개(또는 새로운 기하 단계에서는 세 개) 보다는 하나의 프로세서 어레이를 선호합니다. 통합 프로세서 - 프로세서 어레이의 스레드 상에서 부하 균형 및 논리 파이프라인의 재설계 - 에 대한 공학적 도전은 충분히 가치있는 것으로 인식되었습니다. 이러한 설계는 일반적인 수치 계산에 대한 프로그램 가능한 GPU 프로세서 어레이를 사용하기 위한 기초를 마련하였습니다.
2.1.4. GPGPU
GPU 하드웨어 설계가 보다 통합된 프로세서로 진화되면서 점점 더 고성능 병렬 컴퓨터와 닮아갑니다. DirectX 9-가능 GPU가 사용 가능해 짐에 따라 몇몇 연구자들은 GPU 성능 향상 방향에 대해 인지하고 막대한 계산량이 요구되는 과학과 공학 문제에 GPU를 사용하기 시작하였습니다. 그러나 DirectX 9 GPU는 그래픽스 API가 요구하는 기능들을 충족시키기 위해 설계되어 왔습니다. 계산 리소스에 접근하기 위해서는 프로그래머는 계산이 OpenGL이나 DirectX API 호출을 통해 런칭 가능하도록 네이티브 그래픽스 연산으로 각자의 문제를 대응시켜야만 했습니다. 예를 들어여러 개의 계산 함수의 인스턴스를 동시에 실행하기 위해 계산은 픽셀 셰이더로 작성되어야 했습니다. 입력 데이터의 집합은 텍스쳐 이미지에 저장되어야 하며 삼각형 생성을 통해 GPU로 공급되어야 했습니다. 결과는 래스터 연산으로부터 생성된 픽셀 집합으로 출력되어야 했습니다.
GPU 프로세서 어레이와 프레임 버퍼 메모리 인터페이스가 그래픽스 데이터를 처리하기 위해 설계되었다는 사실은 범용 계산 어플리케이션에 있어서는너무 제한적이었다. 특히 셰이더 프로그램의 출력 데이터는 메모리 위치가 미리 결정 되는 단일 픽셀입니다. 따라서 그래픽스 프로세서 어레이는 메모리 읽기와 쓰기 능력에 있어 매우 제한적이었다. 그림 2.6은 초기 프로그램 가능한 셰이더 프로세서 어레이의 메모리 접근 능력이 매우 제한적이었음을 보여 주고 있습니다. 셰이더 프로그래머들은 입력 데이터를 위한 임의의 메모리 위치를 접근하기 위해 텍스쳐 사용이 불가피했습니다. 더욱 중요한 것은, 셰이더가 메모리에 계산된 메모리 주소를 쓰는 방법이 존재하지 않았는 점입니다. 결과를 메모리에 쓰는 유일한 방법은 픽셀에 컬러 값으로 표시하는 것이었으며, 프레임 버퍼 연산 단계를 2차원 프레임 버퍼에 결과를 출력하도록 설정하였습니다.
더욱이 하나의 패스의 계산에서 다른 패스계산으로 결과를 가져오는 유일한 방법은 모든 병렬 결과를 픽셀 프레임 버퍼에 쓴 후 그 프레임 버퍼를 텍스쳐 맵 입력으로 이용하여 다음 계산 단계에서 픽셀 프래그먼트 셰이더로 입력하였습니다. 사용자 정의 데이터 타입도 존재했습니다: 대부분의 데이터는 1차, 2차 또는 4차 벡터 어레이로 저장됩니다. 현 시대의 일반적인 계산을 GPU로 맵핑하는 일은 참으로 기이한 일이었습니다. 그러함에도 불구하고 용감무쌍(?)한 연구자들은 고통을 감내하는 노력으로 소소하지만 유용한 어플리케이션 시연을 하였습니다. 이 분야는 GPU의 범용 계산(General Purpose Graphics Processing Unit, GPGPU)이라 불리웁니다.
2.3. GPU 계산
Tesla™GPU 아키텍쳐를 개발하는 동안 NVIDIA는 만약 프로그래머들이 GPU와 같은 프로세서를 고려한다면 Tesla의 잠재적 유용성이 훨씬 더 훌륭합니다는 사실을 깨달았다. NVIDIA는 프로그래머들이 그들의 작업을 명시적으로 데이터 병렬화할 수 있는 프로그래밍 접근 방식을 선택하였습니다.
DirectX™10이라는 그래픽스 시대를 맞이하여 NVIDIA는 이미 논리적 그래픽스 파이프라인을 지원하는 다양한 동시 작업을 실행할 수 있는 고성능부동 소수 및 정수 프로세서를 개발하기 시작했습니다. Tesla GPU 아키텍쳐의 설계자들은 또 다른 걸음을 내딛였습니다. 셰이더 프로세서들은 대용량 메모리, 명령 캐시, 명령 시퀀싱 제어 로직을 갖춘 완전히 프로그램 가능한 프로세서가 되었습니다. 추가적인 하드웨어 리소스에 필요한 비용은 다중 쉐어디 프로세서들이 명령 캐시와 명령 시퀀싱 제어 로직을 공유함으로써 절감되었습니다. 동일한 셰이더 프로그램이 무수의 정점이나 픽셀에 적용되어야 하기 때문에 이러한 설계 형태가 잘 맞아 떨어졌습니다. NVIDIA는 컴파일 된 C 프로그램의 요구에 부응하기 위해 랜덤 바이트 어드레싱(addressing) 능력을 갖춘 메모리 로드를 추가하고 명령을 저장하였습니다. 비그래픽 어플리케이션 프로그래머들에게 Tesla GPU 아키텍쳐는 고수준 병렬 계산 작업을 지원하는 병렬 스레드의 계층 구조, 배리어(barrier) 동기화, 어토믹(atomic) 연산을갖춘 보다 범용적인 병렬 프로그래밍 모델을 소개하였습니다. NIVIDA는 CUDA C/C++ 컴파일러, 라이브러리, 런타임 소프트웨어를 개발하여 프로그래머들이 쉽게 새로운 데이터-병렬 계산 모델에 접근하고 어플리케이션을 개발할 수 있도록 하였습니다. 프로그래머들은 더 이상 GPU 병렬 계산 능력을 활용하기 위해 그래픽스 API를 사용할 필요가 없다. G80 칩은 Tesla 아키텍쳐를 기반으로 하고 있으며 GeForce 8800 GTX에서 사용되었는데 차후에 G92와 GT200이 이를 계승하였습니다.
2.2.1. 확장 가능한 GPU
확장성은 시작부터 그래픽스 시스템의 매력적인 특징이었습니다. 초기 워크스테이션 그래픽스 시스템은 고객들에게 다양한 픽셀 프로세서 회로 보드로 선택의 폭을 제공했습니다. 1990년대 중반 이전에 PC 그래픽스 확장은 거의 존재하지 않았습니다. 다만 한 가지 옵션이 있었습니다: 바로 VGA 컨트롤러였습니다. 3D 능력을 갖춘 가속기가 나타나면서 시장에 다양한 선택권이 주어졌습니다. 1998년 3dfx는 그들의 Voodoo2 - 이 시대에는 최고의 성능을 자랑했습니다 - 상에 오리지널 스캔 라인 인터리브(Scan Line Interleave, 이하 SLI)를 갖춘 멀티보드 확장을 소개했습니다. 같은 해인 1998년, NVIDIA는 Riva TNT Ultra(고성능) 및 Vanta(저비용)의 단일 아키텍쳐에 여러 가지 변화를 시도한 다양한 제품을 소개하였습니다. 이들 제품은 우선 속도와 패키징에 신경을 썼으며 나중에는 분리된 칩(GeForce 2 GTS 및 GeForce 2 MX)으로 설계하였습니다. 현재의 아키텍쳐 세대에서는 데스크탑 PC 성능과 가격의 다양한 범위에 대한 요구를 충족시키기 위해 네 개에서 다섯 개의 칩 설계가 필요합니다. 게다가 노트북와 워크스테이션 시스템에서 분리형 제품이 출시되고 있습니다. 2001년 3dfx를 인수한 후, NVIDIA는 멀티 GPU SLI 컨셉을 이어 나가고 있습니다. 예를 들어 GeForce 6800은 프로그래머와 사용자에게 모두에게 멀티 GPU 확장성을 투명하게 제공하고 있습니다. 기능적 거동은 확장 범위에 상관없이 동일합니다. 하나의어플리케이션은 아키텍쳐 패밀리의 모든 제품군에 있어 동일하게 동작합니다.
멀티코어로 전환에 따라 CPU는 단순히 단일 코어의 성능 향상이 아닌 거의 일정한 성능 코어의 수를 증가하여 보다 많은 수의 트랜지스터로 확장하고 있습니다. 현재 산업은 쿼드코어에서 헥스와 옥타코어 CPU로 전환되고 있습니다. 프로그래머들은 이러한 프로세서들을 완벽하게 활용하기 위해 4배에서 8배의 병렬화를 구현하도록 강요 받고 있습니다. 이들 중 대다수는 어플리케이션의 다른 작업이 병렬로 처리되는 굵은 조직 병렬화 전략(Coarse-Grained Parallelism Strategy)을 지지하고 있습니다. 이러한 어플리케이션들은 계속하여 배로 증가하는 코어 수에 대비하여 병렬 작업을 위해 다시 작성되어야 합니다. 반면에 고수준 멀티스레드 GPU로 CUDA의 거대한 세밀 조직(Fine-Grained) 데이터 병렬화 사용이 가능합니다. GPU의 효율적인 스레드 지원은 어플리케이션이 거의 페널티 없이 사용 가능한 하드웨어 실행 리소스보다 훨씬 많은 양의 병렬화를 할 수 있도록 돕습니다. GPU 코어 수가 배로 증가하면서 보다 고성능의 병렬화가 가능합니다. 즉, 그래픽스에 대한 GPU 병렬 프로그래밍 모델과 병렬 계산은 투명하고도 휴대 가능한 확장성을 위해 설계 되었습니다. 그래픽스 프로그램이나 CUDA 프로그램은 한 번 작성되면 프로세서 코어 수에 관계없이 GPU에서 실행됩니다.
2.4. 미래 발전 동향
두 말 할 필요도 없이 프로세서 코어의 수는 실리콘공정이 향상됨에 따라 사용 가능한 트랜지스터의 증가에 비례하여 계속해서 증가할 것입니다. 게다가 GPU는 어마어마한 아키텍쳐 진화를 거듭할 것입니다.
데이터 병렬 어플리케이션의 고성능에 대한 시연에도 불구하고 GPU 코어 프로세서는 아직까지는 단순한 디자인입니다. 일련의 아키텍쳐가 계산 장치의 실질적 활용성을 늘려나감에 따라 보다 적극적으로 기술이 발전해 나갈 것입니다. GPU에서의 확장 가능한 병렬 계산은 아직 얼마되지 않았기 때문에 새로운 어플리케이션들이 급속도로 개발되고 있습니다. 끊임없이연구하여 GPU 설계자들은 새로운 머쉰 최적화를 발견하고 실행할 것입니다.
3. 최신 기술 동향
3.1. 다양한 분야에서의 병렬 계산
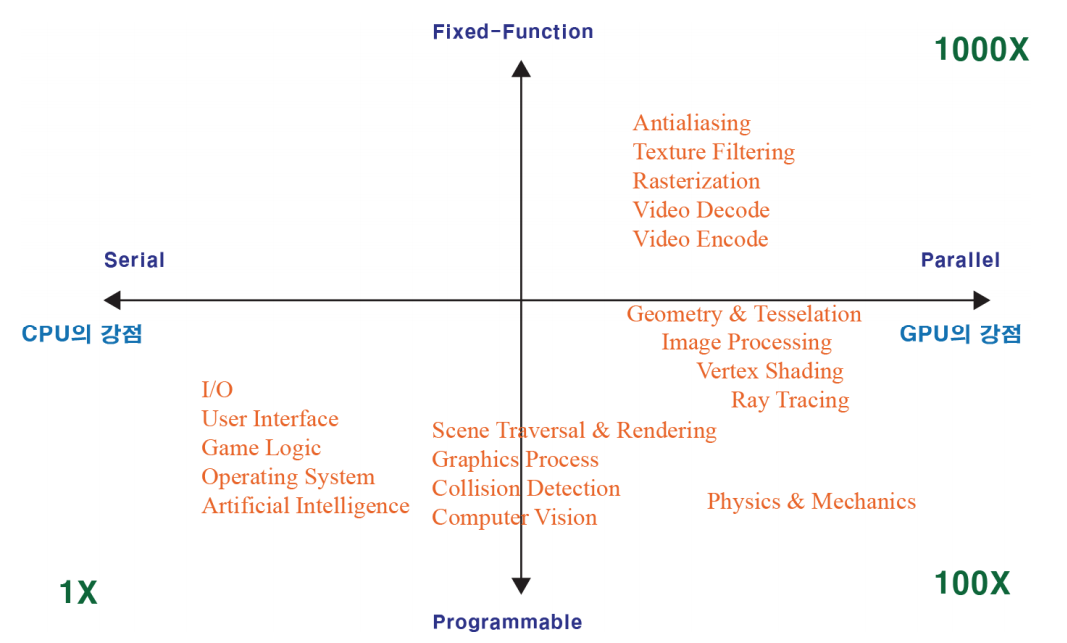
최근 GPU 기술이 그래픽스 처리 뿐만 아니라 일반적인 과학 계산 등을 위한 범용으로의 기능이 확장됨에 따라 막대한 계산량이 요구되는 과학, 공학, 의학 등 여러분야로 활용 범위가 넓어지고 있습니다. 활용 분야를 CPU의 특징으로 대변되는 처리 방식인 직렬 처리(Serial Processing)와 GPU의 대표적 처리 방식인 병렬 처리(Parallel Processing) 방식 및 고정 기능(Fixed-Function)과 프로그램 가능Programmable) 범주로 나눈다면 그림 3.1과 같이 설명할 수 있습니다.
3.2. 하이브리드 GPU 기술
하이브리드 GPU 기술이란 간단히 말해서 CPU와 GPU의 이종 디바이스 간에 메모리 통신을 통해 메모리를 교환하고 병렬 계산에 특화된 GPU에서 계산에 관련된 작업을 처리를 하고 결과를 CPU로 반환하는 기술입니다. 따라서 이 기술의 핵심은 이종 디바이스 간에 데이터 통신과 계산 처리 기술입니다. 자세한 일련의 과정은 다음과 같습니다.
하이브리드 GPU 기술이란 간단히 말해서 CPU와 GPU의 이종 디바이스 간에 메모리 통신을 통해 메모리를 교환하고 병렬 계산에 특화된 GPU에서 계산에 관련된 작업을 처리를 하고 결과를 CPU로 반환하는 기술입니다. 따라서 이 기술의 핵심은 이종 디바이스 간에 데이터 통신과 계산 처리 기술입니다.
자세한 일련의 과정은 다음과 같습니다.
- 입력과 출력에 사용할 데이터를 PC 메모리에 할당합니다.
- 입력과 출력에 사용할 데이터를 그래픽 메모리에 할당합니다.
- 처리하고자 하는 값을 PC 메모리에 입력합니다.
- PC 메모리에 있는 입력 데이터를 그래픽 메모리로 복사합니다.
- 데이터를 분할하여 GPU로 가져옵니다.
- 수천 개 이상의 스레드를 생성하여 커널 함수로 병렬 처리를 합니다.
- 처리된 결과를 병합합니다.
- PC 메모리에 결과를 전송합니다.
- 그래픽 메모리를 해제합니다.
- PC 메모리를 해제합니다.
3.3. 통합 쉐이더 기술
GPU에 사용되는 셰이더는 특화된 일종의 프로세서로 3D 그래픽스 응용 프로그램으로부터 전달 받은 데이터 또는 GPU 내부의 다른 하드웨어 블록으로부터 전달 받은 데이터를 사용자가 기술한 프로그램의 입력으로 받아들여 처리할 수 있습니다. 3D 그래픽스 처리과정에서 각각의 정점 및 픽셀 데이터는 서로 독립적이고 컴포넌트별로 수행되는 연산이 동일한 경우가 대부분이기 때문에 고성능을 목표로 하는 GPU는 다수의 정점 셰이더와 픽셀 셰이더를 병렬로 갖고 있으며 셰이더 내부에도 컴포넌트별 병렬처리 능력을 향상시키기 위한 구조를 택하고 있습니다. 하지만 경우에 따라 지오메트리 단계 또는 래스터화 단계 중 어느 한 쪽에만 연산이 집중되는 경우가 많기 때문에 하드웨어 자원, 즉 셰이더의 효율적인 활용이 어려운 단점이 있습니다.
최근에는 이러한 단점을 보완하여 GPU의 막강한 성능을 충분히 활용하기 위해 통합 셰이더가 등장하였습니다. 통합 셰이더는 정점 셰이더, 픽셀 셰이더 구분 없이 동일한 구조의 셰이더가 하나의 거대한 집단을 이루고 있으며 이들 각각의 셰이더는 경우에 따라 정점 셰이더 또는 픽셀 셰이더로 동작할 수 있기 때문에 경우에 따라 정점 셰이더와 픽셀 셰이더 간 연산 집중도의 불균형문제를 해결할 수 있습니다. 뿐만 아니라 통합 셰이더는 하나의 공통된 명령어 세트(instruction set)를 사용하기 때문에 셰이더 프로그래밍이 보다 용이해졌으며 하드웨어 추가 없이 지오메트리 셰이더 등 다른 기능의 셰이더를 구현할 수 있습니다는 장점이 있습니다.
3.4. NVIDIA의 Fermi 아키텍쳐
2010년에 발표된 Fermi는 GeForce GTX400 이상의 계열에서 사용되는 GPU를 의미합니다. 새로운 Fermi 아키텍쳐는 다음과 같은 특징을 가지고 있습니다:
- 최대 512개의 코어 장착 가능
- 캐시 대역폭을 개선하여 데이터 병렬화 향상
- 이중 정밀도 성능 향상
- 서버에서 사용하던 ECC 지원 - 메모리에서 발생하는 에러 방지
- 트루 캐시(True Cache) 계층구조 - 몇몇 병렬 알고리즘은 GPU의 공유 메모리 사용이 불가능하며 사용자는 공유 메모리 사용을 위해 트루 캐시 아키텍쳐 요청 가능
- 공유 메모리 증가 - 16 KB 이상의 공유 메모리를 통해 어플리케이션 속도 향상
- 컨텍스트 전환 속도 향상 - 어플리케이션 프로그램 간 컨텍스트 전환 속도 향상 및 그래픽스와 계산 간 연산 속도 향상
- 어토믹 연산 속도 향상 - 병렬 알고리즘을 위한 읽기-수정-쓰기 어토믹 연산 속도 향상
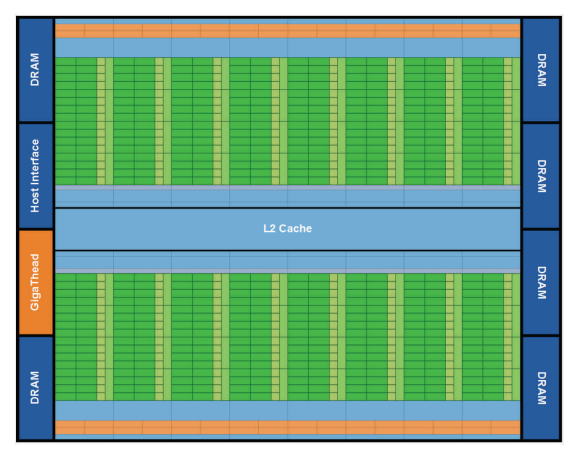
최초의 Fermi 기반 GPU는 30억 개의 트랜지스터로 실행되며 최대 512개의 CUDA 코어를 가지고 있습니다. CUDA 코어는 스레드에 대해 클럭 당 부동 소수 또는 정수 명령을 수행합니다. 512개의 CUDA 코어는 각각 32 코어의 16 SM로 구성됩니다. GPU는 384비트 메모리 인터페이스에 대해 6개의 64비트 메모리 파티션을 가지고 있으며 최대 전체 GDDR5 DRAM의 6GB를 지원합니다. 호스트 인터페이스는 PCI-Express를 통해 GPU와 CPU를 연결다. GigaThread 글로벌 스케쥴러는 스레드 블럭을 SM 스레드 스케쥴러로 분산합니다.
Fermi 아키텍쳐를 구성하는 3세대 스트리밍 멀티프로세서(Streaming Multiprocessor, 이하 SM)는 다음과 같이 구성됩니다:
- 512개 고성능 CUDA 코어
- 16개 불러오기/저장하기 유닛
- 4개의 특수 함수 유닛(Special Function Unit, 이하 SFU)
- 듀얼 워프 스케쥴러64 KB 설정 가능한 공유 메모리와 L1 캐시
다음은 G80, GT200, Fermi 아키텍쳐를 비교한 표입니다.
표 3.1 G80, GT200, Fermi 아키텍쳐 비교
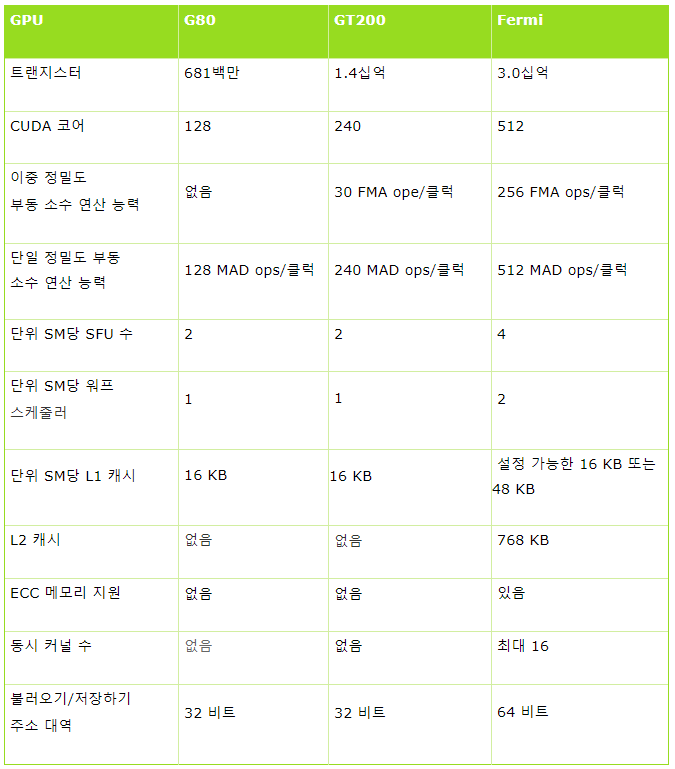
3.5. NVIDIA의 Kepler 아키텍쳐
Kepler 아키텍쳐는 의학, 공학, 금융학 등 많은 영역에서 성장하는 고성능 병렬 계산의 요구에 대응하기 위해 기존의 Fermi 아키텍쳐를 새롭게 정의하여 고성능 계산(High Performance Computing, 이하 HPC)을 더욱 가속화하기 위해 등장한 NVIDIA의 새로운 HPC 아키텍쳐입니다. Kepler GK110 GPU의 주요 특징들은 다음과 같습니다.

-
SMX
Kepler Gk110은 새로운 SMX 유닛을 장착했으며, 이는 지금까지 가장 강력한 스트리밍 멀티프로세서(SM)이며 가장 강력한 프로그램 가능성과 에너지 효율을 지닌 여러 개의 아키텍쳐 혁신으로 이루어 졌습니다.
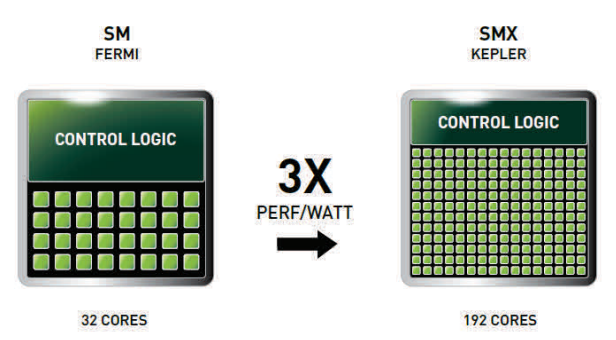
그림 3.4 SMX: 192개의 CUDA 코어, 32개의 특수 함수 유닛, 32개 불러오기/저장하기 유닛(Load/Store units, LD/ST) -
동적 병렬화(Dynamic Parallelism)
동적병렬화는 GPU에게 CPU의 도움 없이 새로운 작업을 스스로 창조하고 결과를 동기화 하며 가속 하드웨어 경로를 통해 작업 스케쥴을 제어하는 능력을 부여합니다. 프로그램 실행 과정에서 병렬화의 양과 형태에 적응할 수 있는 유연성을 제공하여 프로그래머들은 보다 다양한 형태의 병렬 작업에 열중할 수 있으며 GPU 활용에 대한 효율을 극대화 할 수 있습니다. 이 능력은 덜 구조화되고 보다 복잡한 작업을 용이하게 하는 동시에 효과적으로 만들어 어플리케이션의 대부분이 GPU 상에서만 실행될 수 있도록 합니다. 게다가 프로그램은 작성하기 쉬우며 CPU의 자원을 다른 작업에 활용할 수 있습니다.
동적 병렬화는 프로그래머가 모든 내부 병렬 루프를 쉽게 가속하도록 하여 GPU 프로그래밍을 더욱 단순화 합니다 - 결과적으로 GPU는 CPU로 되돌아갈 필요 없이 GPU 상에서 동적으로 스레드를 만듭니다.
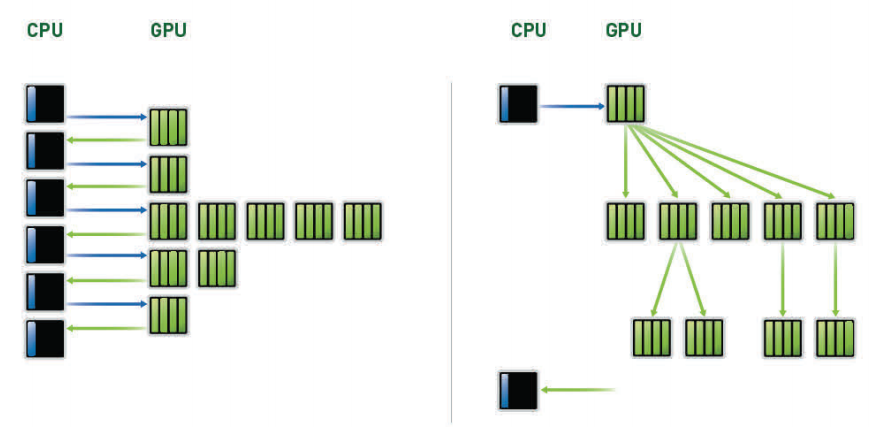
그림 3.5 동적 병렬화. 동적 병렬화 없이는 CPU는 GPU 상의 모든 커널에 접근합니다. Kepler GK110 GPU의 새로운 기능인 동적 병렬화를 통해 CPU와 통신할 필요 없이 내부 커널에 접근할 수 있습니다. -
Hyper-Q
Hyper-Q는 다중 CPU 코어가 단일 GPU 상에 접근할 수 있도록 하여, GPU 활용을 효과적으로 증대시키며 CPU의 유휴 시간(idle time)을 감소시킵니다. Hyper-Q는 32개의 동시적 하드웨어 관리 연결을 허용하여 호스트와 GK110 GPU 간에 전체 접속량을 증가시킵니다 - Fermi에서는 단일 접속만이 가능했습니다. Hyper-Q는 다중 CUDA 스트림, 다중 메시지 전달 인터페이스(MPI) 프로세스 또는 프로세스 내의 다중 스레드로부터 분리된 연결을 허용하는 유연한 솔루션입니다.
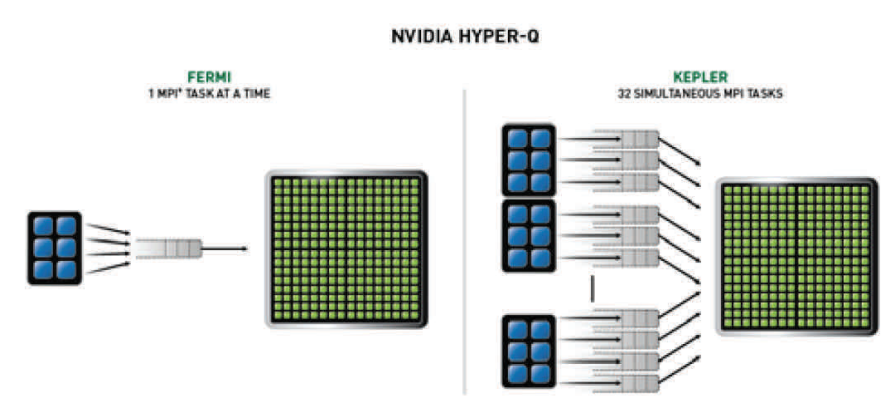
그림 3.6 Hyper-Q는 분리된 작업 큐를 사용하여 모든 스트림이 동시에 작동할 수 있도록 합니다. Fermi 모델에서는 단일 하드웨어 작업 큐에 의한 내부 스트림 의존성으로 인해 동시성이 제한되어 있었습니다. Hyper-Q는 MPI 기반의 병렬 컴퓨터 시스템 사용 시 많은 장점이 있습니다. 레거시 MPI 기반 알고리즘들은 멀티코어 CPU 기반 시스템에서의 작동을 위해 생성되었었습니다. CPU 기반 시스템의 효율적 관리가 가능했던 작업 부하가 일반적으로 GPU를 사용하는 것보다 작기 때문에 각 MPI 프로세스로 전달되는 작업량은 일반적으로 GPU 프로세서를 완전히 차지하기에는 부족합니다. 다중 MPI 프로세스가 동시에 GPU 상에서 작동하는 것은 언제나 문제를 일으킬소지가 있지만 이러한 프로세스들은 잘못된 의존성 때문에 병목화 될 소지가 있습니다. 이로인해 GPU는최대 효율치 보다 낮게 동작합니다. Hyper-Q는 잘못된 의존성 병목 현상을 제거하고 MPI가 시스템 CPU에서 GPU 프로세스로 이동할 수 있는 속도로 증가시킵니다. Hyper-Q는 MPI 어플리케이션에 대한 성능을 부양시킵니다.
-
NVIDIA GPUDirect
NVIDIA GPUDirect는 단일 컴퓨터 또는 네트워크상에 존재하는 서로 다른 서버 내 GPU가 CPU/시스템 메모리를 통할 필요 없이 직접 데이터를 교환할 수 있도록 하는 능력입니다. GPUDirect의 RDMA 특징은 SSD, NIC, IB 어탭터와 같은 써드파티 디바이스들이동일 시스템 내의 여러 GPU 상의 메모리에 접근할 수 있도록 합니다. 따라서 이는 MPI 전송의 레이턴시를 줄이고 GPU 메모리로부터 또는 GPU 메모리로의 메시지를 전달 받습니다. 또한 시스템 메모리 대역폭 요구조건을 완화하고 다른 CUDA 작업을 위한 GPU DMA 엔진을 자유롭게 합니다. Kepler GK110은 위한 P2P와 비디오를 위한 GPUDiect 포함한 다른 GPUDirect 기능들을 지원합니다.
3.6. NVIDIA의 Tesla 프로세서
Tesla는 NVIDIA의 세 번째 GPU이며 GPGPU로써는 처음으로 개발된 것입니다. 이는 고성능 병렬 처리용 워크스테이션의 프로세서로 제작된 제품으로 기존의 CPU 기반의 수퍼컴퓨터를 대체하기 위해 만들어졌습니다. 따라서 그래픽스 카드에서 사용하는 3D 가속과 같은 그래픽스 처리용 기능을 제거하고 오직 범용적인 계산만을 할 수 있습니다. 사무실에서 사용하는 수퍼컴퓨터를 목표로 합니다고 할 수 있습니다. Tesla 프로세서는 보드 당 448개의 어플리케이션 가속 코어를 장착하여 부동 소수 계산 성능 가속을 위해 CPU의 병렬 계산 부담을 완화합니다.
주요 스펙, 기능 및 특징은 다음과 같습니다:
표 3.2 Tesla 프로세서의 주요 테크니컬 스펙
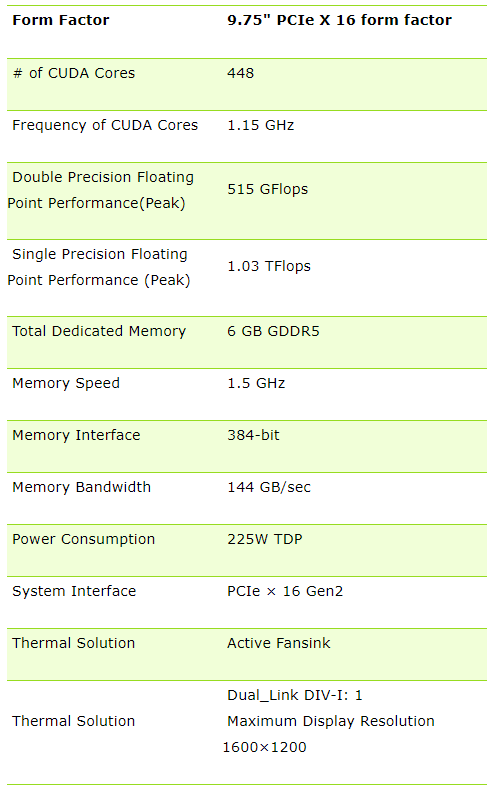
표 3.3 Tesla 프로세서의 주요 특징 및 기능
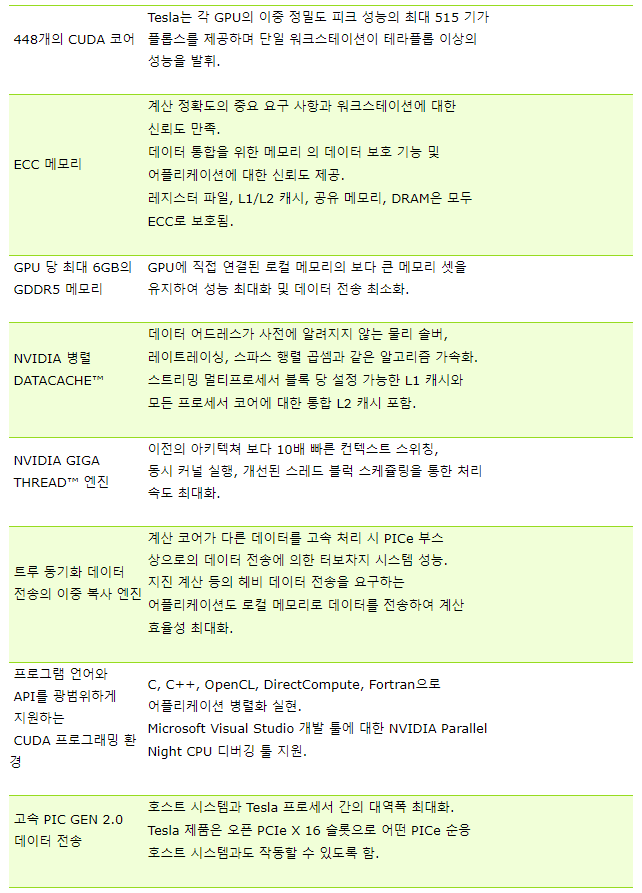
4. 컴퓨터 그래픽스 산업 분야에서의 GPU 활용
NVIDIA는 컴퓨터 그래픽스 분야에서의 엔드유저 활용성을 높이기 위해 자사의 GPU를 활용하는 제품군을 자체 개발 또는 서드파티 제품을 인수하였습니다. 본 장에서는 GPU를 통한 성능 최적화를 기대할 수 있는 NVIDIA의 컴퓨터 그래픽스 관련 솔루션에 대한 소개를 하고 본 보고서를 마무리하고자 합니다.
4.1. PhysX
PhysX는 2004년 NovodeX로부터 스핀오프 된 Ageia가 개발한 NVIDIA의 GPU를 활용한 멀티스레드 실시간 물리 엔진 미들웨어 SDK입니다. 게임 엔진 미들웨어라 함은 게임 개발자가 복잡한 물리 상호 작용에 대한 코드를 직접 작성하지 않고도 게임에서의 물리 현상을 구현할 수 있도록 하는 툴입니다. PhysX는 최근 사용되는 게임 엔진 중 하나이며 Microsoft Windows, Mac OS X, Linux, PlayStation 3, Xbox360, Wii 등에서 사용 가능합니다. PhysX SDK는 무료, 상업용 또는 비상업용으로 모든 플랫폼의 개발자에게 제공됩니다.
PhysX가 제공하는 주요 물리 시뮬레이션의 타입은 다음과 같습니다:
- 강체(Rigid Body) 동역학
- 연체(Soft Body) 동역학
- 랙달(Ragdolls) 및 캐릭터 컨트롤러
- 차량 동역학
- 볼륨 플루이드 시뮬레이션
- 옷감(Cloth) 시뮬레이션 (찢어짐, 압축 포함)
- 볼륨메트릭 포스 필드(Force Field) 시뮬레이션
NVIDIA가 Ageia를 인수한 PhysX의 개발은 기존의 PPU(물리 처리 장치, Physics Processing Unit) 확장 카드에서 벗어나 현대 GPU의 GPGPU 성능에 초점을 맞추게 되면서 무수한 GPU의 스레드를 활용하여 방대한 양의 물리 계산을 초고속으로 할 수 있게 되었습니다. CUDA 프로그래밍이 가능한 GeForce 그래픽스 카드(최소 32 코어와 256MB의 비디오 메모리를 갖춘 시리즈 8 및 상위 시리즈)가 PhysX를 사용할 수 있습니다. ForaceWare 드라이버의 버전 186과 그 상위 버전은 AMD와 같은 다른 제조사의 GPU인 경우PhysX 하드웨어 가속을 무력화 시켜 놓았습니다. NVIDIA의 대표는 이 사안이 개발 비용, 품질 보장 및 사업상의 이유로 인한 것이라고 고객들에게 설명하고 있습니다.
2010년 7월 5일 Real World Technologies사는 PhysX 아키텍쳐에 대한 분석서를 발행하였습니다. 이 분석서에 따르면 이 시기에 PhysX 어플리케이션에서 사용되는 대부분의 코드는 멀트스레드 최적화가 없는 x87 명령 구조에 기반하고 있다고 명시되어 있습니다. 이는 CPU 상에서 PhysX 코드를 실행 시 현저한 성능 저하 현상이 나타날 수 있는 원인이 됩니다. 이 분석서는 SSE 명령 구조를 이용한 PhysX 코드의 재작성이 CPU PhysX와 GPU PhysX 간의 성능 차이를 줄일 수 있다고 제안하였습니다.
4.2. OptiX
OptiX는 NVIDIA의 GeForce, Quadro, Tesla 시리즈 등과 같은 CUDA 기반 비디오 카드를위한 실시간 광선 추적 엔진(Ray Tracing Engine, 이하RT 엔진)입니다. 컴퓨터 그래픽스에서의 광선 추적이란 이미지 평면의 픽셀을 통해 빛의 경로를 추적하여 이미지를 생성하는 기법입니다. 비단 컴퓨터 그래픽스 분야 뿐만 아니라 광선 추적은 오브젝트의 충돌 감지, 사운드 전파, 가시성 판단 등에도 활용될 수 있습니다.
OptiX는 이러한 분야의 모든 광선 추적 기술을 포함하며, NVIDIA CUDA GPU 컴퓨팅 아키텍쳐를 기반으로 하여 GPU의 성능을 활용하여 광선 추적의 속도를 매우 빠르게 계산하는 미들웨어 SDK입니다.
GPU 성능을 활용하기 때문에 OptiX는 이전에 수 분이 걸리던 광선 추적 계산을 몇 밀리 초 내에 계산을 할 수 있도록 하였으며 실세계 씬의 빛의 반사, 굴절, 그림자 변화를 인터랙티브 형식으로 즉석으로 확인할 수 있게 되었습니다. 현재 OptiX의 이상적인 하드웨어는 NVIDIA Quadro와 Tesla입니다.
지정된 룩(look)을 제공하는 일반적인 렌더러와는 달리, OptiX 엔진은 유연한 광선 추적 플랫폼이며 개발자들은 이를 통해 광선 추적 관련 작업을 수월하게 할 수 있습니다. OptiX 엔진의 "유연성"의 의미는 절차적 정의로의 확장 및 데이터 크기를 최소화 할 수있는 하이브리드 렌더링 접근 기법으로의 확장을 의미하며 속도와 사실성 추구 간의 적절한 균형을 맞출 수 있습니다.
초고속 광적 추적의 잠재성은 자동차 스타일링, 설계 시각화, 시각효과 등의 산업 뿐만 아니라 광학 및 음향학 설계, 방사능 연구, 충돌 해석 등과 같은 비렌더링 분야로 확장되고 있습니다.
OptiX 엔진에 의한 인터랙티브 광선 추적은 이후에 설명한 NVIDIA SceniX 씬 관리 엔진으로 구동되는 어플리케이션에도 매우 유용하며, 이를 활용해 개발자들은 신속하게 어플리케이션을 구현할 수 있습니다.
4.3. SceniX
SceniX는 NVIDIA가 개발한 씬 관리 엔진으로서 오늘날 프로페셔널 실시간 3D 그래픽스 어플리케이션의 다양한 요구에 부응하기 위해 개발된 인터랙티브 코어입니다. SceniX 엔진은 통합이 용이한 프레임워크 내에서 액터랙티비티(Interactivity)와 사실성을 제공하여 실시간으로 3D 데이터가 필요하거나 의사결정 및 결과를 전달하는 자동차 스타일링, 시각화, 시뮬레이션, 방송 그래픽스, 인터랙티브 훈련, 에너지 개발 등 산업 분야에서의 다양한 상용 및 개인용 어플리케이션 개발을 위한 기초 도구의 역할을 합니다.
SceniX 엔진은 NVIDIA Quadro 그래픽스 솔루션의 성능을 중심으로 가장 효율적인 씬 관리와 실시간 렌더링 제공하기 위해 최신 GPU를 활용하고 있습니다. SceniX 어플리케이션은 stereo, SDI, 30비트 컬러, 씬 분배, 인터랙티브 광선 추적 등의 기능들을 제공하고 있습니다.
현재 SceniX에서 제공하는 주요 기능들을 정리하면 다음과 같습니다:
- 3D 어플리케이션을 위한 견고한 크로스 플랫폼 기반
- 최대 렌더링 옵션과 품질을 위한 CgFX 지원
- 씬 관리 및 렌더링의 지속적인 속도 개선
- 인터랙티브 어플리케이션 빌드를 위한 무료 지원
그림 3.7은 SceniX의 소프트웨어 스택을 설명하고 있습니다.
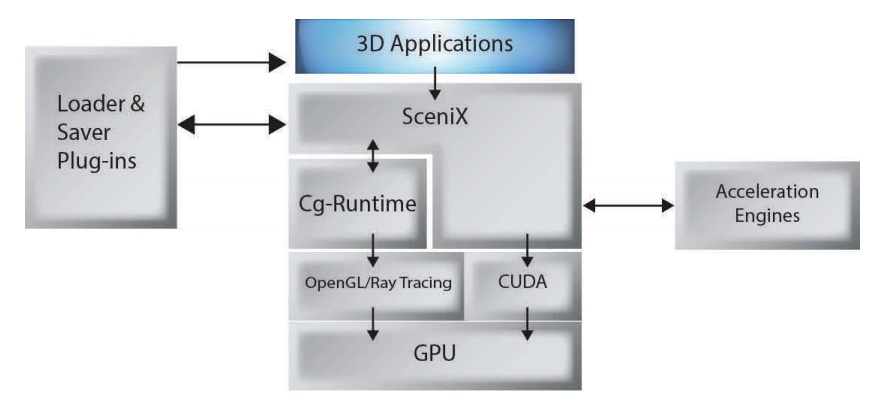
4.4. CompleX
CompleX 씬 스케일링 엔진은 NVIDIA가 소프트웨어 개발자들로 하여금 NVIDIA Quadro Plex 비주얼 컴퓨팅 시스템에서의 다중 GPU를 활용한 성능 및 메모리를 최적화하여 극도로 복잡한 씬의 성능을 향상시킬 수 있도록 하기 위해 개발한 엔진입니다. CompleX 엔진은 기존의 OpenGL 어플리케이션과의 직접적인 통합 또는 NCIDIA SceniX를 기반으로 개발 된 이플리케이션의 옵션을 쉽게 활성화 할 수 있습니다.
한 번 통합되기만 하면, CompleX는 여러 GPU에 걸쳐 씬 지오메트리를 분산시키고 결과를 합성하여 끊김없는 고품질의 인터랙티브 경험을 제공합니다.
CompleX 엔진의 주요 기능은 다음과 같습니다:
- 여러 GPU에 걸쳐 자동으로 지오메트리 로드를 분산하고 끊김없는 결과로 합성
- 4개의 Quadro Plex D2 또는 2개의 Quadro Plex S4 시스템을 이용하여 최대 8 GPU와 32 GB의 메모리로 확장
- SceniX, OpenSceneGraph, Open Inventor에 대한 직접적인 지원
- 모든 OpenGL 씬 그래프와의 커스텀 통합을 위한 CompleX SDK 제공
- 두 개의 매칭되는 Quadro FX 보드와의 "개발자 모드" 연계
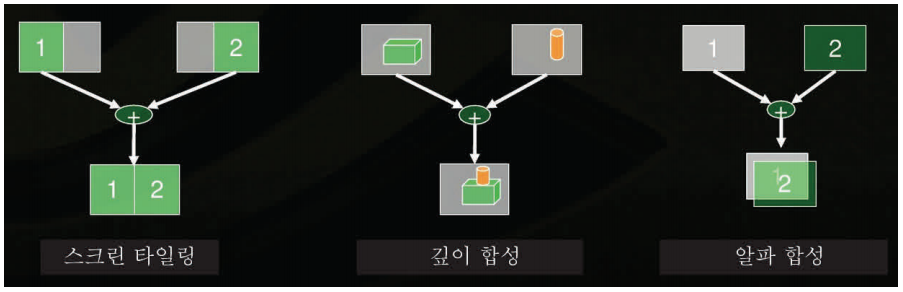
CompleX SDK의 이미지 합성 도구의 원리는 스크린 타일링, 깊이 합성, 알파 합성으로 이루어지면 현재 CompleX의 이미지 합성 도구가 지원하는 플랫폼은 Windows 64와 Linux64입니다. 그림 3.8은SceniX의 이미지 합성 원리를 설명하고 있습니다.
5. 맺음말
지금까지 그래픽 처리 장치 GPU에 대한 개념 및 역사 그리고 최신 기술 동향과 더불어 GPGPU를 최초로 개발한 NVIDIA의 GPU 활용 솔루션에 대해 소개하였습니다. 본 보고서의 GPU에 대한 내용이 다소 NVIDIA사의 솔루션 위주로 작성된 것 같은 아쉬움이 남지만 적어도 현재까지는 NVIDIA가 GPU 기술로는 단연 으뜸임을 인정하지 않을 수 없다. 물론 이 기술이 어느 회사 하나의 독점이 아닌 여러 회사의 경쟁에 의해 더욱 발전할 것이므로 AMD의 가속 처리 장치(Accelerated Processing Units, 이하 APU)의 기술이 급속도로 진전되고 있다는 사실은 매우 반가운 소식입니다. GPU 기술 경쟁에 의해 GPU 기술 발전의 가속화와 더불어 사용자는 더욱 값싼 가격으로 개인용 수퍼컴퓨터를 운용할 날이 그리 멀지 않은 것 같습니다. 아니, 이미 대중화가 실현되고 있습니다. 한편으로는 NVIDIA의 CUDA 또는 OpenCL과 같은 GPU 기반 수퍼컴퓨팅용 프로그래밍 언어가 빠르게 개발되고 있는 것을 보면 영화의 VFX 퀄리티 수준의 극사실적인 실시간 렌더링 구현이 가능한 날이 얼마남지 않은 것으로 기대됩니다.
불과 몇 년 전에 개인용 컴퓨터로 3D 그래픽스 렌더링을 할 수 있습니다고 감탄했었는데 이제는 개인용 컴퓨터로 수퍼컴퓨터급의 어플리케이션을 구동할 수 있다고 하니 감개무량합니다. 수퍼컴퓨팅 기술은 앞으로 더욱 급속도로 발전할 것입니다. 또한 미래의 그래픽스 관련 어플리케이션은 대부분의 연산을 실시간으로 처리하는 방향으로 발전할 것입니다 - 현재의 어플리케이션은 라이트 맵 기술이라든가 오브젝트 프랙쳐 시뮬레이션 등 과도한 연산이 요구되는 부분은 선행 계산을 통해 런타임에서의 연산 부담을 경감시켰습니다. 이러한 기술 트렌드에 발 맞추어변화에 적응하는 것을 뛰어 넘어 변화를 이끌어 가려면 GPU 기반의 수퍼컴퓨팅 기술을 신속하게 흡수하여야 할 것입니다.