지난 포스팅에서는 개발단계 수준에서의 데이터 샤딩에 대하여 알아보았다. 실제 어플리케이션의 서비스 단계에서는 보다 안정성이 요구되기 때문에 이번 글에서는 이에 필요한 설정에 대해 알아보도록 하겠습니다.
데이터 운용의 안정성을 위해서는 다음과 같은 항목들이 요구됩니다:
- 다중의 config server들
- 다중의 mongos server들
- 각 샤드에 대한 리플리카(Replica) 구성
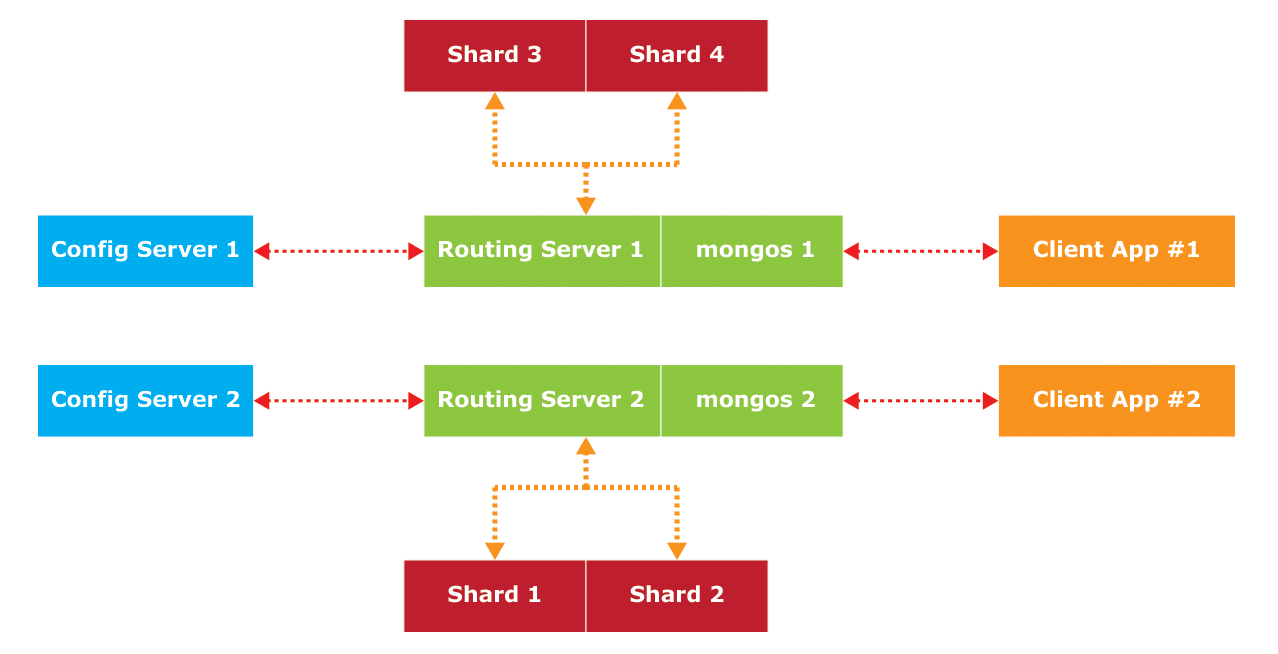
샤딩에 대한 내용을 다루면서 익숙치 않은 많은 용어들이 한꺼번에 등장하여 혼란스러울 수 있으므로 다음 그림을 통해 전체적인 용어와 이들의 관계에 대하여 이해하도록 합니다.
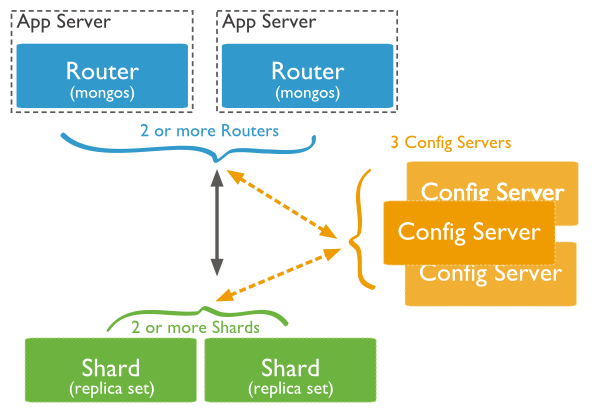
[그림 1.]의 샤드 클러스터 예를 보면, 이는 3개의 Config Server들과 2개 이상의 mongos Router(어플리케이션 서버) 및 2개 이상의 샤드(Replica Set)로 구성되어 있음을 알 수 있습니다.
지난 포스팅에서도 언급하였었지만 각각의 역할에 대해 간단히 언급하면 다음과 같습니다:
Shard(Replica Set)는 데이터를 저장하는 저장소입니다. 프로덕션 레벨에서의 샤드 클러스터에 있어 높은 가용성과 데이터 일치성을 위해 각 샤드는 리플리카 세트가 됩니다.
Query Router 또는 mongos 인스턴스는 클라이언트 어플리케이션에 대한 인터페이스 역할을 하며 해당 샤드(들)에게 연산을 수행하도록 합니다. 즉, 클라이언트 어플리케이션으로부터 요청을 받아 해당 샤드(들)에게 연산을 수행하도록 명령하고 해당 샤드(들)에게로부터 결과를 받아 클라이언트 어플리케이션에 전달하는 역할을 합니다. 클라이언트 요청에 대한 부담을 분산하기 위해 샤드 클러스터는 여러 개의 Query Router를 가질 수 있으며, 서비스를 위한 대부분의 경우 많은 Query Router를 구성하도록 합니다.
Config Server는 클러스터의 메타데이터를 저장합니다. 이 데이터는 클러스터의 데이터 세트를 샤드들에 맵핑하는(연관짓는) 것에 대한 것입니다. Query Router는 이 메타데이터를 이용하여 특정 연산에 해당하는 샤드를 어떤 것인지 파악합니다. 실제 서비스를 하는 프로덕션 레벨에서는 정확히 3개의 Config Server를 갖습니다.
이제 본격적으로 예제를 통해 프로덕션 레벨의 샤드 클러스터를 구성해 보겠습니다. 사용된 머쉰의 대수는 2대이며, 이해를 돕기위해 머쉰 및 서버 구성은 다음 표와 같습니다:
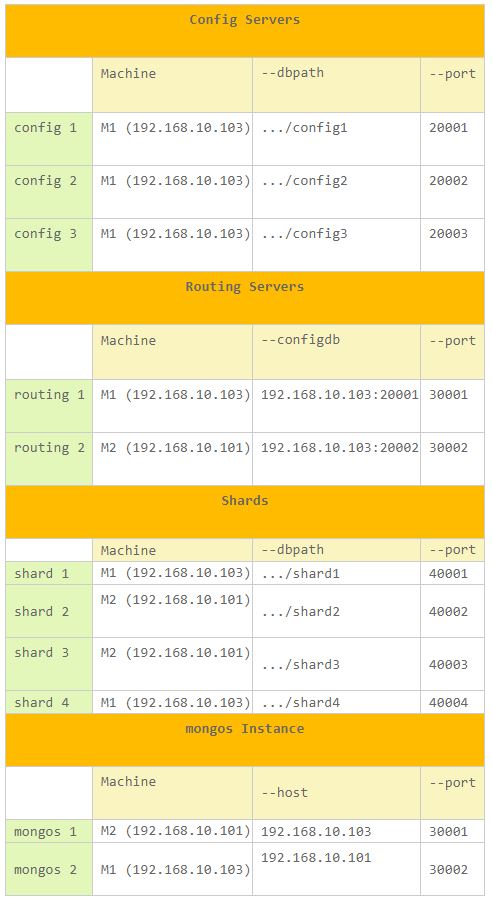
샤드 클러스터 구성 정보를 표로 정리해 보았는데, 꽤 복잡해 보일 것입니다. 샤드 클러스터 구성에 대한 이해를 돕기 위해 오히려 구성을 좀 더 복잡하게 하였습니다. 총 2대의 머쉰을 사용하였는데 첫번째 머쉰 M1의 IP주소는 192.168.10.103이며, 두번째 머쉰 M2의 IP주소는 192.168.10.101입니다. 각자의 머쉰에 따라 IP주소는 다르니 유의하기 바랍니다.
표에서 "Machine"이라고 표현한 부분은 각 구성요소의 서버가 실행되는 머쉰을 의미합니다. 위의 표를 바탕으로 전체 샤드 클러스터 구성도를 작성하면 다음과 같습니다:
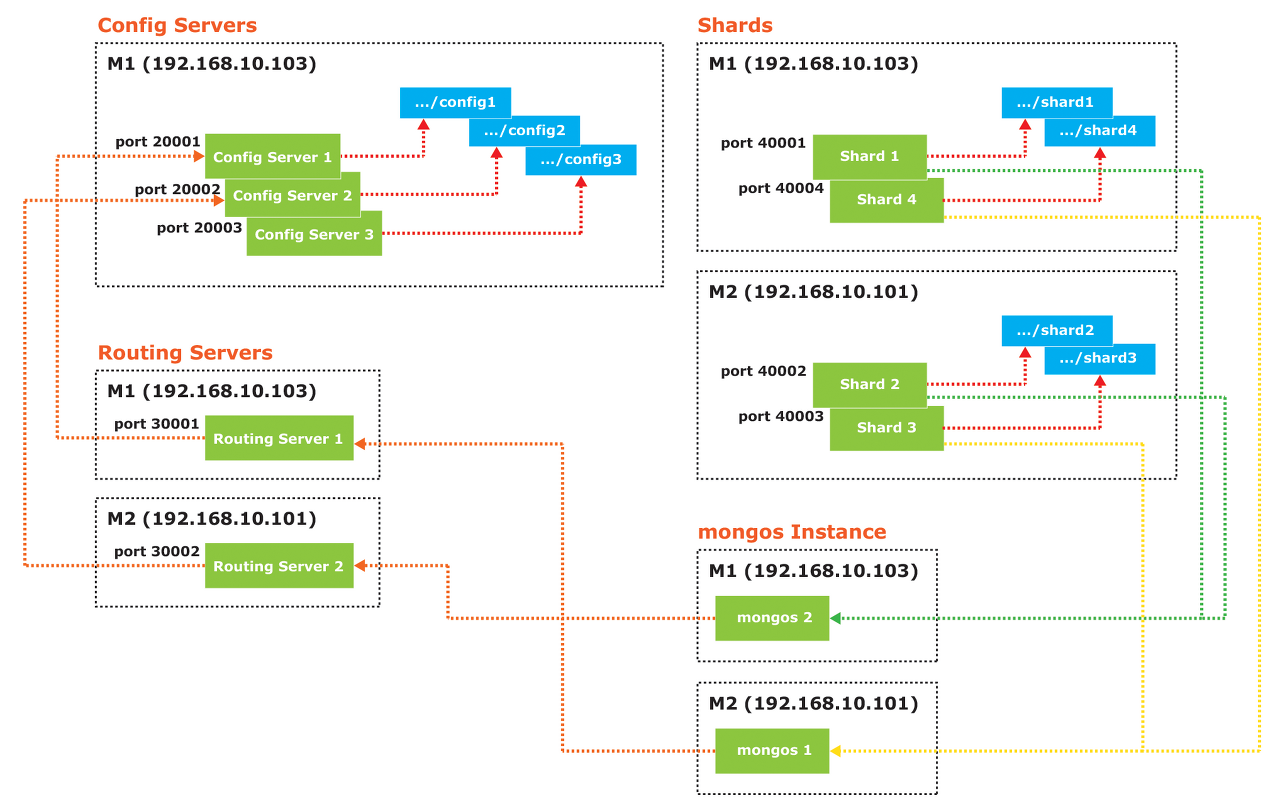
다중의 Config Server들 [그림 2.]에서 보는 바와 같이 Config Server들 M1에서만 설정하였습니다.
Config Server 1에 대한 mongod 인스턴스 실행은 다음과 같습니다:
$ mongod --configsvr --dbpath /[YOUR_DB_PATH]/config1 --port 20001
Config Server 2에 대한 mongod 인스턴스 실행은 다음과 같습니다:
$ mongod --configsvr --dbpath /[YOUR_DB_PATH]/config2 --port 20002
Config Server 3에 대한 mongod 인스턴스 실행은 다음과 같습니다:
$ mongod --configsvr --dbpath /[YOUR_DB_PATH]/config3 --port 20003
다중의 Routing Server들
mongos 인스턴스 또는 Routing Server는 원하는 만큼 설정이 가능하나 클라이언트 어플리케이션 서버의 수만큼 설정하는 것이 일반적입니다.
[표 1.]에서 보는 바와 같이 Routing Server 1은 M1에서 실행되며, Routing Server 2는 M2에서 실행됩니다.
Routing Server 1에 대한 mongos 인스턴스 실행은 다음과 같습니다:
$ mongos --configdb 192.168.10.103:20001 --port 30001
Routing Server 2에 대한 mongos 인스턴스 실행은 다음과 같습니다:
$ mongos --configdb 192.168.10.103:20002 --port 30002
Shard 설정
[표 1.]에서 보는 바와 같이 Shard 1과 Shard 4는 M1에서 실행되며, Shard 2와 Shard 3는 M2에서 실행됩니다.
Shard 1에 대한 mongod 인스턴스 실행은 다음과 같습니다 (M1에서 실행):
$ mongod --dbpath /[YOUR_DB_PATH]/shard1 --port 40001
Shard 2에 대한 mongod 인스턴스 실행은 다음과 같습니다 (M2에서 실행):
$ mongod --dbpath /[YOUR_DB_PATH]/shard2 --port 40002
Shard 3에 대한 mongod 인스턴스 실행은 다음과 같습니다 (M2에서 실행):
$ mongod --dbpath /[YOUR_DB_PATH]/shard3 --port 40003
Shard 4에 대한 mongod 인스턴스 실행은 다음과 같습니다 (M1에서 실행):
$ mongod --dbpath /[YOUR_DB_PATH]/shard4 --port 40004
mongos 인스턴스 실행
[표 1.]과 같이 mongos 1은 M2에서, mongos 2는 M1에서 실행합니다.
mongos 1에 대한 실행 명령은 다음과 같습니다 (M2에서 실행):
$ mongo --host 192.168.10.103 --port 30001
mongos 2에 대한 실행 명령은 다음과 같습니다 (M1에서 실행):
$ mongo --host 192.168.10.101 --port 30002
mongos 1과 mongos 2에 대해 mongos 인스턴스 실행 시 디폴트 db는 test이므로 다음과 같이 admin db로 이동합니다 (각각의 mongos 명령 쉘에서 실행해야 합니다):
mongos> use admin
switched to db admin
앞서 언급한 바와 같이 mongos 인스턴스의 개수는 클라이언트 어플리케이션의 개수와 동일하게 설정합니다고 하였습니다. 즉, 본 예제의 경우 2개의 mongos 인스턴스를 실행합니다는 것은 클라이언트 어플리케이션 또한 2개인 것을 가정하고 있습니다.
Shard 추가
이제 모든 서버 인스턴스 실행은 마무리 되었다. 남은 것은 샤드를 추가하는 것입니다. 총 4개의 샤드 서버가 실행 중이며 현재 실행되고 있는 mongos 명령 쉘에서 "addShard" 명령을 통해 이들을 추가합니다.
M1에서 실행되고 있는 mongos 2(클라이언트 어플리케이션 #2)에 shard 1을 추가합니다:
mongos> db.runCommand({addShard: "192.168.10.103:40001"})
{ "shardAdded" : "shard0000", "ok" : 1 }
M1에서 실행되고 있는 mongos 2(클라이언트 어플리케이션 #2)에 shard 2를 추가합니다:
mongos> db.runCommand({addShard: "192.168.10.101:40002"})
{ "shardAdded" : "shard0001", "ok" : 1 }
M2에서 실행되고 있는 mongos 1(클라이언트 어플리케이션 #1)에 shard 3를 추가합니다:
mongos> db.runCommand({addShard: "192.168.10.101:40003"})
{ "shardAdded" : "shard0001", "ok" : 1 }
M2에서 실행되고 있는 mongos 1(클라이언트 어플리케이션 #1)에 shard 4를 추가합니다:
mongos> db.runCommand({addShard: "192.168.10.103:40004"})
{ "shardAdded" : "shard0001", "ok" : 1 }
데이터 샤딩 이제 길고 길었던 여정이 어느덧 마무리 되어 가는 듯 하다. 마지막으로 데이터 샤딩만 남았습니다.
우선 클라이언트 어플리케이션 #1(mongos 1)에 대한 데이터를 입력합니다. mongos 1의 명령 쉘에서 jobs라는 이름의 db로 이동합니다:
mongos> use jobs
switched to db jobs
그리고 이 db에 다음과 같이 데이터가 존재합니다고 하겠습니다:
mongos> db.tasks.insert({todo : "shopping", status : "READY", priority : "4", _id: 1})
mongos> db.tasks.insert({todo : "studying Mongo DB", status : "READY", priority : "1", _id: 2})
mongos> db.tasks.insert({todo : "reporting the current job", status : "DONE", priority : "8", _id: 3})
mongos> db.tasks.insert({todo : "cleaning my room", status : "READY", priority : "3", _id: 4})
mongos> db.tasks.insert({todo : "meeting friends", status : "DONE", priority : "7", _id: 5})
mongos> db.tasks.insert({todo : "depositing money", status : "RUNNING", priority : "6", _id: 6})
mongos> db.tasks.insert({todo : "take a walk", status : "RUNNING", priority : "5", _id: 7})
mongos> db.tasks.insert({todo : "sending an email", status : "READY", priority : "2", _id: 8})
입력된 데이터를 살펴보면 다음과 같습니다:
mongos> db.tasks.find().pretty()
{ "_id" : 1, "todo" : "shopping", "status" : "READY", "priority" : "4" }
{
"_id" : 2,
"todo" : "studying Mongo DB",
"status" : "READY",
"priority" : "1"
}
{
"_id" : 3,
"todo" : "reporting the current job",
"status" : "DONE",
"priority" : "8"
}
{
"_id" : 4,
"todo" : "cleaning my room",
"status" : "READY",
"priority" : "3"
}
{
"_id" : 5,
"todo" : "meeting friends",
"status" : "DONE",
"priority" : "7"
}
{
"_id" : 6,
"todo" : "depositing money",
"status" : "RUNNING",
"priority" : "6"
}
{
"_id" : 7,
"todo" : "take a walk",
"status" : "RUNNING",
"priority" : "5"
}
{
"_id" : 8,
"todo" : "sending an email",
"status" : "READY",
"priority" : "2"
}
샤딩을 활성화하기 위해 다시 admin db로 이동합니다:
mongos> use admin
switched to db admin
enableSharding 명령을 입력하여 jobs db에 대한 데이터를 샤딩합니다:
mongos> db.runCommand({enableSharding: "jobs"})
{ "ok" : 1 }
이번에는 클라이언트 어플리케이션 #2 (mongos 2)에 대한 데이터를 샤딩합니다. mongos 1에 대한 내용과 방식은 동일하며 db 이름과 데이터만 다를 뿐입니다. mongos 2의 명령 쉘에서 users라는 이름의 db로 이동합니다:
mongos> use users
switched to db users
이 db에 다음과 같이 데이터가 존재합니다고 하겠습니다.
mongos> db.member.insert({user: "cinema4d", pwd: "1234", email: "aaa@gmail.com"})
mongos> db.member.insert({user: "raspberry01", pwd: "asdf", email: "bbb@gmail.com"})
mongos> db.member.insert({user: "ozerodie", pwd: "asdf", email: "ccc@gmail.com"})
mongos> db.member.insert({user: "nicesubi", pwd: "asdf", email: "ddd@gmail.com"})
입력된 데이터를 살펴보면 다음과 같습니다:
mongos> db.member.find().pretty()
{
"_id" : ObjectId("535920a5e1679452b81e1b83"),
"user" : "cinema4d",
"pwd" : "1234",
"email" : "aaa@gmail.com"
}
{
"_id" : ObjectId("535920a6e1679452b81e1b84"),
"user" : "raspberry01",
"pwd" : "asdf",
"email" : "bbb@gmail.com"
}
{
"_id" : ObjectId("535920a6e1679452b81e1b85"),
"user" : "ozerodie",
"pwd" : "asdf",
"email" : "ccc@gmail.com"
}
{
"_id" : ObjectId("535920a7e1679452b81e1b86"),
"user" : "nicesubi",
"pwd" : "asdf",
"email" : "ddd@gmail.com"
}
샤딩을 활성화하기 위해 다시 admin db로 이동합니다:
mongos> use admin
switched to db admin
enableSharding 명령을 입력하여 users db에 대한 데이터를 샤딩합니다:
mongos> db.runCommand({enableSharding: "users"})
{ "ok" : 1 }
이번 예제는 샤딩을 연습하기 위해 꽤 복잡한 샤드 클러스터를 구성하여 보았습니다. 결국 클라이언트 어플리케이션과의 연계성을 포함하여 전체 구성을 그림으로 표현하면 다음과 같습니다.