Written by Alex Choi, Feb. 10, 2019.
이번 포스팅에서는 Object Detection의 초기 어플리케이션인 R-CNN의 속도와 정확도를 개선한 Fast R-CNN에 대하여 간단하게 알아보도록 하겠습니다.
R-CNN의 단점
그러면 우선 기존의 R-CNN이 가지고 있는 단점이 무엇인지 살펴보겠습니다.
-
R-CNN에서는 하나의 이미지에서 Selective Search를 통하여 최대 2,000개의 Region Proposals를 생성하고 각각에 대하여 ConvNet(가령, AlexNet)에 대한 Forward Pass를 연산합니다. 이는 학습시간도 상당한 시간이 요구되지만 Runtime에서는 사용할 수 있는 수준이 되지 못합니다.
-
R-CNN에서는 세 개의 모델을 별도록 학습시킵니다:
- Image Features를 추출하기 위한 CNN Model
- 이미지를 분류하기 위한 Classifier
- 바운딩 박스를 실제 오브젝트 위치에 정합하기 위한 Bounding Regressor
그런데, 이 3개의 모델을 별도로 학습시키는 것은 효율적이지 않습니다.
Fast R-CNN의 등장
위에 언급된 R-CNN의 단점을 극복하기 위해 R-CNN 논문의 저자인 Roos Girshick은 2015년에 아래와 같은 새로운 논문을 발표합니다:
위 논문의 2가지 핵심 아이디어는 다음과 같습니다.
Idea 1: RoI Pooling
R-CNN은 이미지 상에서 Region Proposals를 생성 시, 이들의 영역이 서로 겹치는 경우가 많아 불필요하게 CNN의 반복적인 Forward 계산(최대 2,000번)으로 계산 효율성을 떨어뜨립니다. Ross가 제안한 아이디어는 이미지 상이 아닌 CNN의 Feature Map 상에서 RoI(Region of Interest)를 추출하는 것입니다. 즉, CNN의 Forward Pass는 하나의 이미지에 대하여 딱 한 번만 수행하여 Feature Map을 얻고, 최대 2,000개의 Region Proposals 간에 Fearue Map을 서로 공유할 수 있도록 하는 것입니다.
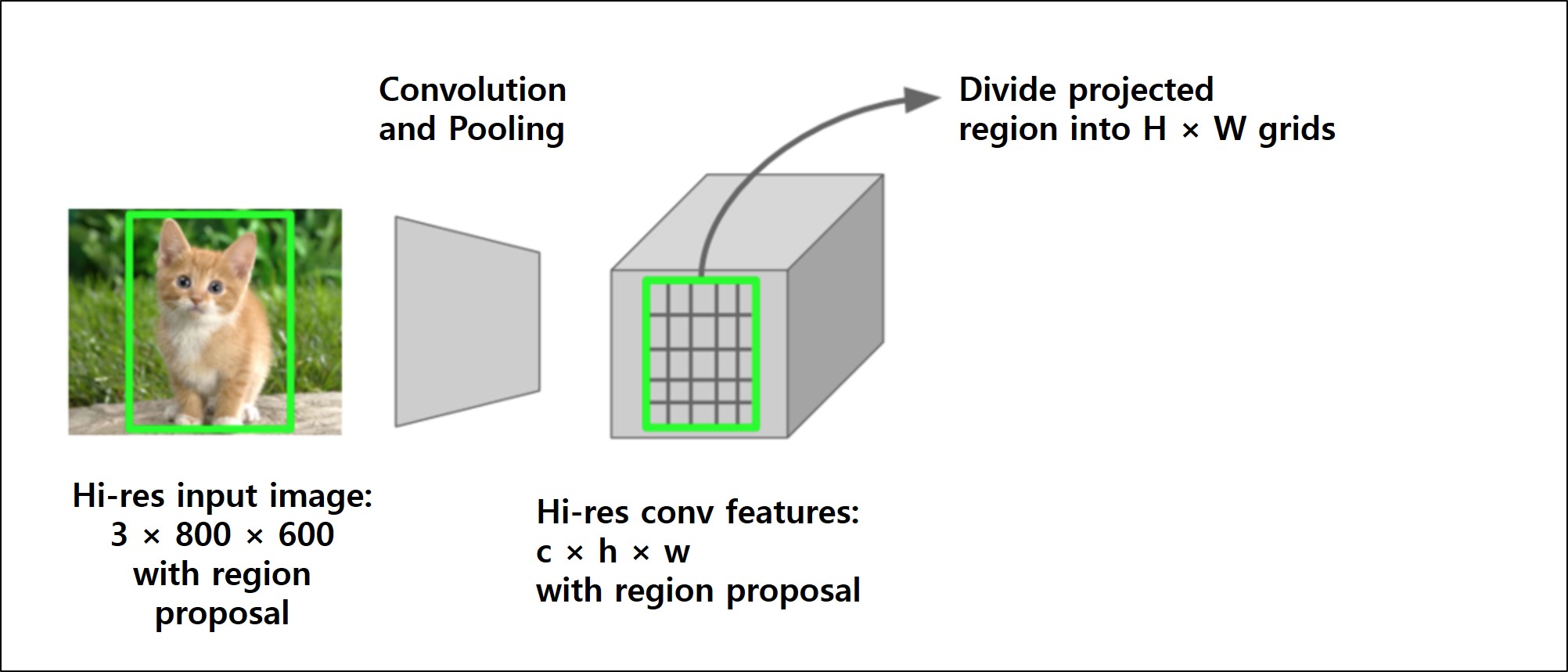
위의 이미지는 입력 이미지로부터 CNN에 대하여 Forward Pass하여 Conv Feature Map을 얻고, Region Proposal 영역을 Feature Map 상에 투영(Projection)한 후, 이를 정해진 차원(Dimension, 가로-세로 해상도)로 영역을 분할합니다.
가령, 3 × 800 × 600(채널 수 = 3, 높이 = 800, 넓이 = 600)의 입력 이미지를 CNN에 Forward Pass하여 얻는 Conv Feature Map의 상에 투영된 Region Proposal 영역의 차원이 \(C × h × w\) 라고 하면, 이 영역을 각 채널에 대하여 \(H × W\) 개수로 분할합니다(\(H\)와 \(W\)를 Layer Hyper-parameters라고 합니다).
RoI Max-pooling은 \(h × w\) 크기의 RoI Windows를 \(H × W\) 개수만큼의 Sub-window로 분할하므로 각 Sub-window의 크기는 대략 \(h/H × w/W\)이 되며, 각 Sub-window 내의 값들을 Max-pooling하여 Grid Cell로 출력합니다.
Idea 2: 하나의 네트워크에서 모두 트레이닝
Fast R-CNN의 두번째 핵심 아이디어는, (1) Feature 학습을 위한 CNN, (2) 분류를 위한 Classifier(SVM), (3) 바운딩 박스를 오브젝트에 정합시키는 Regression (Linear Regressor)을 각각 트레이닝하는 R-CNN과는 달리, Fast R-CNN은 이 세가지를 하나의 네트워크 내에서 학습시킵니다.
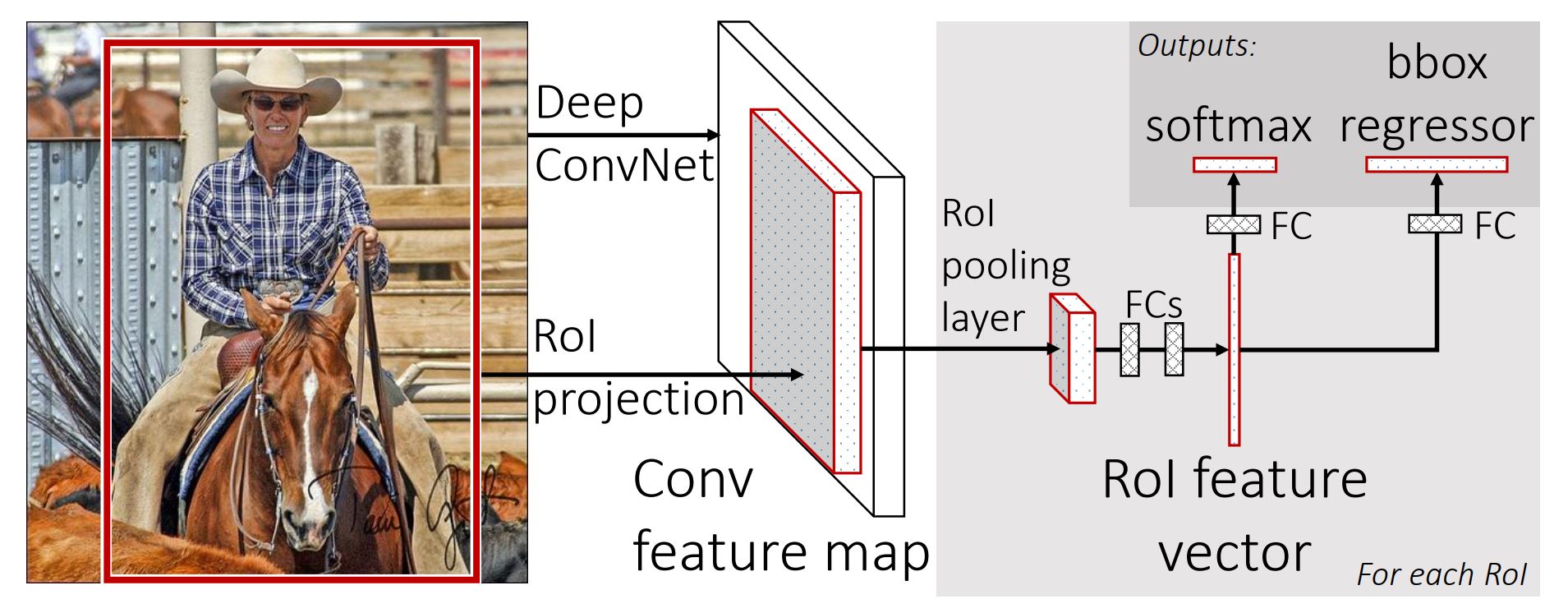
위의 이미지를 자세하게 살펴보면 다음과 요약할 수 있습니다:
- 입력 이미지를 CNN에 대하여 Forward Pass하여 Conv Feature Map을 얻고, Max-pooling Layer를 얻습니다.
- 프로젝션 된 각각의 RoI에 대하여 Pooling Layer는 Conv Feature Map으로부터 고정된 크기의 Feature Vector를 추출합니다.
- 각각의 Feature Vector는 일련의 Fully Connected(FC) Layer를 거쳐서
- \(K\)개의 클래스 + 배경 클래스에 대한 Softmax 확률을 구합니다.
- 각각의 \(K\)개의 오브젝트 클래스에 대한 4개의 변수 - \((r,c,w,h)\) - 바운딩 박스의 왼쪽 상단 모서리 좌표 \((r,c)\) 및 크기 \((w,h)\) - 를 출력합니다.
지금까지 Fast R-CNN을 이용한 Object Detection에 대하여 알아보았습니다. 다음 포스팅에서는 Faster R-CNN을 이용한 Object Detection에 대하여 알아보도록 하겠습니다.